函数
函数:组织好的、可以重复利用的、用户实现单一或者关联功能的代码段,函数能够提高应用的模块性和代码的重复利用率。
函数的定义规则
函数代码块以def关键词开头,后接函数标识符名称和圆括号()
任何传入参数和自变量必须放在圆括号中间
函数的第一行语句可以选择性的使用文档字符串----用于存放函数说明
函数内容以冒号起始,并且缩进
定义函数
语法:
def 函数名([参数列表]): #参数列表可选项函数体
例如:
def PName(): #使用def定义一个函数PName()
print('hello world')
PName() #调用函数调用函数
python内置了很多函数,内置函数可以直接调用,调用一个函数需要知道函数的名称和函数的参数。
语法:
函数名([参数列表])
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋值给一个变量,相当于给这个函数起了一个别名。
例如:
student = [1,2,3,4,5]
a = len #变量a指向len函数
num = a(student) #可以通过a调用len函数
print('student列表元素的个数为:',num)
结果为:
student列表元素的个数为: 5
注意:
1.遇到行数定义时,不会去执行内部代码,只有遇到函数调用时,才会去执行函数体内部代码
2.执行完内部代码后,又回到调用函数的地方,继续向下执行
3.如果没有调用函数的话,函数体内部代码是不会执行的函数的参数
位置参数:调用函数时根据函数定义的参数位置来传递参数
例如:定义一个参数,函数有3个参数name,age,gender
def UserInfo(name,age,denger):
print(f'你的名字为:{name},年龄为:{age},性别为:{denger}')
UserInfo('张三',18,'男') #需要放实参,个数和位置需要和形参一一对应,否则报错
结果为:
你的名字为:张三,年龄为:18,性别为:男关键字参数:函数调用时通过"键" = "值"形式加以指定,可以让函数更加清晰、容易使用。
例如:
def getInfo(name,address):
print('大家好我叫%s,我来自%s'%(name,address))
getInfo(name='张三',address='西藏') #给实参加上关键字,关键字对应形参
结果为:
大家好我叫张三,我来自西藏参数的默认值:在声明函数的时候给形参先赋值,携带默认值形参放在最右边
例如一:
def getInfo(name,address = '西藏')
print('大家好我叫%s,我来自%s'%(name,address))
getInfo('张三') #有默认值的形参,可以不用传递
结果为:
大家好我叫张三,我来自西藏
例如二:
def getInfo(name,address = '西藏')
print('大家好我叫%s,我来自%s'%(name,address))
getInfo('张三','新疆') #传递参数,会覆盖原来的默认值
结果为:
大家好我叫张三,我来自新疆不定长参数:也叫可变参数,用于不确定会传递多少参数的时候使用;
*args是接收所有未命名的参数(关键字),返回的结果是元组类型;
**kwargs是接收所有命名的实参(关键字),返回的结果是字典类型
例如:
def getInfo(name,address,*args,**kwargs):
print('大家好我叫%s,我来自%s'%(name,address))
print(args) #返回是元组类型
print(kwargs) #返回是字典类型
getInfo('张三','新疆','a','b','c',age = 18)
结果为:
大家好我叫张三,我来自新疆
('a','b','c')
{'age',18}可变对象与不可变对象(传递的时候)
不可变类型:如整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在fun(a)内部修改a的值,只是修改另一个赋值的对象,不会影响a本身。
例如:
def sign(): #自定义函数
print('_'*30)
#值传递 不可变对象传递
def fun(args)
args = 'hello' #重新赋值
print(args) #输出hello
str = 'baby' #声明一个字符串变量,不可变数据类型
fun(str1) #将该字符串传递到函数中
sign()
print(str1) #还是baby,并没有被改变
结果为:
hello
------------------------------
baby可变类型:如列表、字典。如fun(la),则是将la真正的传递过去,修改后fun外部的la也会受到影响
例如:
def sign(): #自定义函数
print('_'*30)
#引用传递 可变对象传递
def fun(args):
args[0] = 'hello' #重新赋值
print(args) #输出hello
list1 = ['baby','come on'] #声明一个字符变量,可变数据类型
fun(list1) #将该字符传递到函数中
sign()
print(list1) #传递的对象本身,函数里面被修改了值,源对象也会修改
结果为:
['hello', 'come on']
------------------------------
['hello', 'come on']
函数的返回值
函数并非总是将结果直接输出,相反,函数的调用者需要函数提供一些通过函数处理过后的一个或者一组数据,只有调用者拥有了这个数据,才能够做一些其他的操作。那么这个时候,就需要函数返回给调用者数据,这个就被成为返回值,想要在函数中把结果返回给调用者,需要在函数中使用return。
return语句:用于退出函数,选择性的向调用者返回一个表达式。直接return的语句返回None。
def max(x,y):
if x > y:
return x #结束函数的运行,并且将结果返回给调用的地方
else:
return y
# print(y) #没有执行代码
#return后的代码不会执行
#调用函数 接收返回值
num = max(3,2) #声明一个变量num接收调用的函数后的返回值
print(num) #观察接收的返回值
结果为:
3return返回多个值
def sum(x,y):
return x,y
num = sum(1,2) #用一个变量接收多个返回值时,会保存在一个元组中
print(num)
num1,num2 = sum(1,2)
print(num1)
print(num2)
结果为:
(1, 2)
1
2yield 生成器:把一个函数变成一个generator,使用生成器可以达到延迟操作的效果,所谓延迟操作就是指在需要的时候产生结果,而不是立即产生结果,节省资源消耗和声明一个序列不同的生成器,在不使用的时候几乎是不占内存。
例如:
def getNum(n):
i = 0
while i <= n:
yield i #将函数变成一个generator生成器对象
i += 1
# 调用函数
getNum(5)
a = getNum(5) #把生成器赋值给一个变量a
# 使用生成器,通过next()方法
print(next(a)) #输出yield返回的值,输出一次返回一个值
print(next(a))
结果为:
0
1例如:
#for循环遍历一个生成器
a = (x for x in range(10000000)) #是一个生成器,不是元组推导式
print(a)
for i in a:
print(next(a))send():把值传进当前的yield
例如:
def gen():
i = 0
while i <=5:
temp = yield i #不是一个赋值
#使用yield是一个生成器
print(temp) #因为yield之后返回结果到调用者的地方,暂停运行
i += 1
a = gen()
next(a)
print(a.send('我是a')) #可以将值发送到上一次yield的地方
结果为:
我是a
1迭代器
迭代对象:
可以用for i in 遍历的对象可以叫做迭代对象:Iterable
如可迭代对象:list string dict
可以被next()函数调用的并不断返回下一个值的对象叫做迭代器:iterator
凡是可以用作与next()函数的对象都是iterator迭代器例如:
list01 = [1,2,3,4,5] #是一个可迭代对象
#通过iter()将可迭代对象变成迭代器
a = iter(list01)
print(next(a))
print(next(a))
结果为:
1
2变量的作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
局部变量:声明在函数内部的变量,局部变量的作用域只在于函数中,外部无法使用
例如:
def test01():
a = 10
print('-----修改前的a:%d'%(a))
print(id(a))
a = 20
print('-----修改后的a:%d'%(a))
print(id(a))
def test02():
a = 40
print('-----我是test02的a:%d'%(a))
print(id(a))
test01()
test02()
结果为:
-----修改前的a:10
140722366292672
-----修改后的a:20
140722366292992
-----我是test02的a:40
140722366293632全局变量:声明在函数外部的变量,大家共同使用;
a = 100
print('打印全局变量a:%d'%(a))
print(id(a))
def test1():
print('在test1函数内部使用全局变量a:%d'%(a))
print(id(a))
def test2():
print('在test2函数内部使用全局变量a:%d'%(a))
print(id(a))
#调用函数
test1()
test2()
结果为:
打印全局变量a:100
140722366295552
在test1函数内部使用全局变量a:100
140722366295552
在test2函数内部使用全局变量a:100
140722366295552修改全局变量:global关键字
a = 100
print('打印全局变量a:%d'%(a))
print(id(a))
def test1():
global a
a = 200
print('在test1函数内部使用修改全局变量a:%d'%(a))
print(id(a))
def test2():
print('在test2函数内部使用全局变量a:%d'%(a))
print(id(a))
#调用函数
test1()
test2()
print('打印全局变量a:%d'%(a))
print(id(a))
结果为:
打印全局变量a:100
140722366295552
在test1函数内部使用修改全局变量a:200
140722366298752
在test2函数内部使用全局变量a:200
140722366298752
打印全局变量a:200
140722366298752匿名函数:定义函数的过程中,没有给定名称的函数,python中使用lambda表达式来创建匿名函数
lambda创建匿名函数规则
lambda 参数列表:表达式
lambda只是一个表达式,函数体比def简单很多
lambda的主体是一个表达式,而不是一个代码块,所以不能写太多的逻辑进去
lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间的参数
lambda定义的函数的返回值就是表达式的返回值,不需要return语句块
lambda表达式的主要应用场景就是复制给变量、作为参数传入其他函数例如:
1.没有参数的匿名函数
s = lambda : '哈哈哈'
print(s())
结果为:
哈哈哈
2.有参数的匿名函数
s = lambda x,y : x + y
print(s(3,3))
结果为:
6
3.矢量化的三元运算符
s = lambda x,y : x if x > 2 else y
print(s(3,5))
结果为:
3需求:字典排序
dic = {'a':1,'c':2,'b':3}
dic = sorted(dic.items(),key=lambda x:x[1],reverse= True)
print({k:v for k,v in dic})
结果为:
{'b': 3, 'c': 2, 'a': 1}
需求:列表排序
list01 = [
{'name':'joe','age':18},
{'name':'susan','age':19},
{'name':'tom','age':17}
]
dic = sorted(list01,key = lambda x:x['age'],reverse= True) #reverse=True 是倒序,由大到小,reverse=False或者不填是正序,有小到大
print(dic)
结果为:
[{'name': 'susan', 'age': 19}, {'name': 'joe', 'age': 18}, {'name': 'tom', 'age': 17}]递归函数:递归就是子程序(或函数)直接调用自己或通过一系列调用语句简介调用自己,是一种描述问题和解决问题的基本方法。
例如:
def main(n):
print('进入第%d层梦境'%n)
if n == 3:
print('到达潜意识区,开始醒来')
else:
main(n+1)
print('从第%d层梦境醒来'%n)
main(1)
结果为:
进入第1层梦境
进入第2层梦境
进入第3层梦境
到达潜意识区,开始醒来
从第3层梦境醒来
从第2层梦境醒来
从第1层梦境醒来计算阶乘
def jiecheng(n):
if n == 1:
return 1
else:
return n * jiecheng(n-1)
print(jiecheng(10))
结果为:
3628800高阶函数:将一个函数做为参数传递到另一个函数A中,那个这个函数A就是高阶函数
map接收一个函数及多个集合序列,会根据提供的函数对指定序列做映射,然后返回一个新的map
例如:
list01 = [1,3,5,7,9]
list02 = [2,4,6,8,10]
new_list = map(lambda x,y:x * y,list01,list02)
print(list(new_list)) #将map对象转换为list
结果为:
[2, 12, 30, 56, 90]filter用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的filter对象
list02 = [2,4,6,8,10]
new_list = filter(lambda x:x > 4,list02)
print(list(new_list))
结果为:
[6, 8, 10]reduce对于序列中的所有元素用func进行数据合并操作,可以给定一个初始值
from functools import reduce
list02 = [2,4,6,8,10]
new_list = reduce(lambda x,y:x+y,list02)
print(new_list)
结果为:
30文件的操作
open函数
语法:
open(name[,mode[,bufferning[,encoding]]])
name:包含了要访问的文件名称的字符串值[区分绝对路径和相对路径]
mode:决定了打开文件的模式:只读,写入,追加等。
buffering:如果buffering的值被设置为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果buffering的值设置为大于1的整数,表明了是寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。关闭文件
语法:
文件对象.close()
例如:
file = open('1.txt,'w')
file.close()文件读写
read(num):可以读取文件里面的内容。num表示要从文件读取的数据长度(单位是字节),如果没有传入num,那么表示读取文件中所有的数据
语法:
read(num)
例如:
#读取操作
f = open('test.txt','r')
content = f.read(5)
print(content)
print('_'*30)
content = f.read()
print(content)
f.close()
结果为:
1
2
3
______________________________
4
5
6
7
open文件
用open结合for循环逐行读取
files = open('python.txt','r',encoding='utf-8')
i = 1
for line in files:
# 没有使用read
print('这是第%d行内容:%s'%(i,line),end='')
i += 1
files.close()
结果为:
这是第1行内容:123456789
这是第2行内容:SADFASDFwith...open
关键字with在不在需要访问文件后将其关闭。可以让python去确定:你只管打开文件,并在需要时使用它,python自会在合适的时候自动将其关闭;
也可以使用open()和close()来打开和关闭文件,但这样做,如果程序存在bug,导致close()语句未执行,文件将不会关闭。
#用with结合for
with open('python.txt','r',encoding='utf-8') as files:
i = 1
for line in files:
print('这是第%d行内容:%s'%(i,line),end='')
i += 1
结果为:
这是第1行内容:123456789
这是第2行内容:SADFASDF访问模式


文件的读
readlines:可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
语法:
readlines()
例如:用open与for循环进行逐行读取
f = open('test.txt','r',encoding='utf-8')
content = f.readlines()
i = 1
for list1 in content:
print('这是第%d行内容:%s'%(i,list1),end='')
i += 1
f.close()
结果为:
这是第1行内容:1
这是第2行内容:2
这是第3行内容:3
这是第4行内容:4
这是第5行内容:5
这是第6行内容:6
这是第7行内容:7
例如:用with与for循环进行逐行读取
with open('test.txt','r',encoding='utf-8') as files:
contents = files.readlines()
i = 1
for list1 in contents:
print('这是第%d行内容:%s'%(i,list1),end='')
i += 1
结果为:
这是第1行内容:1
这是第2行内容:2
这是第3行内容:3
这是第4行内容:4
这是第5行内容:5
这是第6行内容:6
这是第7行内容:7写入文件
1.如果要写入的文件不存在,函数open()将自动创建。
2.使用文件对象的访问write()讲一个字符串写入文件,这个程序是没有终端输出
3.函数write()不会再写入的文本末尾添加换行符,需要手动添加\n
注意:python只能将字符串写入文本文件,要将数值数据存储到文本文件中,必须先使用函数str()将其转换为字符串格式。
例如:
files = open('python.txt','w',encoding='utf-8')
content = 'hello world!'
content = '一起耍,可以吗??'
files.write(content) #写入数据
files.close()
例如:
with open('python.txt','a',encoding='utf-8') as files:
content = '\n滚蛋!'
files.write(content)常用函数


tell查看文件指针
例如:python.txt文件内容是:1234567890
files = open('python.txt','r',encoding='utf-8')
str = files.read(5)
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
str = files.read()
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
files.close()
结果是:
当前读取的数据是:12345
当前的位置是: 5
当前读取的数据是:67890
当前的位置是: 10seek()设置指针
例如:python.txt文件内容是:1234567890
files = open('python.txt','r',encoding='utf-8')
str = files.read(5)
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
# 重新设置文件的指针
files.seek(2,0)
str = files.read(2)
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
files.close()
结果为:
当前读取的数据是:12345
当前的位置是: 5
当前读取的数据是:34
当前的位置是: 4面向对象
面向对象:
面向对象就不像面向过程那样按照功能划分模块了,它所关注的是软件系统有哪些参与者,把这些参与者称为对象,找出这些软件系统的参与者也就是对象之后,分析这些对象有哪些特征、哪些行为,以及对象之间的关系,所以说面向对象的开发核心是对象
类
类是对象的类型,具有相同属性和行为事物的统称。类是抽象的,在使用的时候通常会找到这个类的一个具体存在
对象
万物皆对象,对象拥有自己的特征和行为。
类和对象的关系
类是对象的类型,对象是类的实例。类是抽象的概念,而对象是一个你能够摸得着,看得到的实体。二者相辅相成,谁也离不开谁
创建和使用类
定义类:
class 类名():
#文档说明
属性
方法
注意:类名要满足标识符命名规则,同时要遵循大驼峰命名习惯
例如:
class Person():
'''这是一个人类'''
country = '中国' #声明类属性,并且赋值
#实例属性同构造方法来声明
#self不是关键字,代表的是当前对象
def __init__(self,name,age,sex): #构造方法
#构造方法不需要调用,在实例化的时候自动调用
self.name = name
self.age = age
self.sex = sex
#创建普通方法
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}') #在方法里面使用实例属性
#实例化对象
people01 = Person('joe',18,'男') #在实例化的时候传参
#通过对象调用实例方法
people01.getName()
结果为:
我的名字叫:joe,年龄是:18,性别是:男,我来自:中国类的属性分类

访问属性
class Person():
country = '中国'
def __init__(self,name,age,sex):
self.name =name
self.age = age
self.sex = sex
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}')
people01 = Person('joe',18,'男')
print(people01.name) #通过对象名.属性名,访问实例属性(对象属性)
print(people01.age)
print(people01.sex)
结果为:
joe
18
男针对类的属性的一些方法
可以使用点实例化对象名+.来访问对象的属性,也可以使用以下函数的方式来访问属性
class Person():
country = '中国'
def __init__(self,name,age,sex):
self.name =name
self.age = age
self.sex = sex
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}')
people01 = Person('joe',18,'男')
1.访问对象的属性 getattr(obj, name[, default])
print(getattr(people01,'name'))
结果为:
joe
2.检查是否存在一个属性hasattr(obj,name),存在为True,不存在为False
print(hasattr(people01,'name'))
结果为:
True
3.设置一个属性setattr(obj,name,value) 。如果属性不存在,会创建一个新属性
print(setattr(people01,'name','susan')) #不存在返回None
print(people01.name)
结果为:
None
susan
4.删除属性delattr(obj, name)
delattr(people01,'name')
print(people01.name) #在此print执行会报错
注意:name需要加单引号,obj为实例化对象名称内置属性
class Person():
country = '中国'
def __init__(self,name,age,sex):
self.name =name
self.age = age
self.sex = sex
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}')
people01 = Person('joe',18,'男')
1.__dict__ : 类的属性(包含一个字典,由类的属性名:值组成) 实例化类名.__dict__
print(people01.__dict__)
结果为:
{'name': 'joe', 'age': 18, 'sex': '男'}
2.__doc__ :类的文档字符串 (类名.)实例化类名.__doc__
print(people01.__doc__)
结果为:
这是一个人类
3.__name__: 类名,实现方式 类名.__name__
print(Person.__name__)
结果为:
Person
4.__bases__ : 类的所有父类构成元素(包含了以个由所有父类组成的元组)
print(Person.__bases__)
结果为:
(<class 'object'>,)init ()构造方法和self
init ()是一个特殊的方法属于类的专有方法,被称为类的构造函数或初始化方法,方法的前面和后面都有两个下划线。
这是为了避免Python默认方法和普通方法名称的冲突。每当创建类的实例化对象的时候, init ()方法都会默认被运行。作用就是初始化已实例化后的对象。
在方法定义中,第一个参数self是必不可少的。类的方法和普通的函数的区别就是self,self并不是Python的关键字,只是按照惯例和标准的规定,推荐使用self。
name
name :如果放在Modules模块中,表示的是模块的名字,如果放在class类中,表示的是类的名字
main :模块,xxx.py文件本身被直接执行时,对应的模块名就是 main _ 了
可以在 if name == " main _":中添加自己想要的,用于测试模块,演示模块用法等代码作为模块,被别的Python程序导入时,模块名就是本身文件名了。
继承
程序中定义一个class的时候,可以从某个现有的class继承,新的class成为子类(Subclass),而被继承的class称之为基类、父类或超类。子类继承了其父类所有属性和方法,同事还可以定义自己的属性和方法。
例如:
#声明一个父类
class Animal():
def __init__(self,name,food):
self.name = name
self.food = food
def eat(self):
print('%s爱吃%s'%(self.name,self.food))
#声明一个子类继承Animal
class Dog(Animal):
def __init__(self,name,food,drink):
super(Dog,self).__init__(name,food)
#子类自己的属性
self.drink = drink
#子类自己的方法
def drinks(self):
print('%s爱吃%s'(self.name,self.food,self.drink))
class Cat(Animal):
def __init__(self,name,food,drink):
super(Cat,self).__init__(name,food)
#子类自己的属性
self.drink = drink
#子类自己的方法
def drinks(self):
print(f'%s爱吃%s'(self.name,self.food,self.drink))
#重写父类的eat
def eat(self):
print('%s特别爱吃%s'%(self.name,self.food))
dog1 = Dog('金毛','骨头','可乐')
dog1.eat()
dog1.drinks()
cat1 = Cat('波斯猫','鱼','雪碧')
cat1.eat()
cat1.drinks()
结果为:
金毛爱吃骨头
金毛爱喝可乐
波斯猫特别爱吃鱼
波斯猫爱喝雪碧多继承
语法格式如下:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
注意:圆括号中父类的顺序,如果继承的父类中有相同的方法名,而在子类中使用时未指定,python将从左到右查找父类中是否包含方法class A():
def a(self):
print('我是A里面的a方法')
class B():
def b(self):
print('我是B里面的b方法')
def a(self):
print('我是B里面的a方法')
class C():
def c(self):
print('我是C里面的c方法')
class D(A,B,C):
def d(self):
print('我是D里面的d方法')
dd = D()
dd.d() #调用自己的方法
dd.c()
dd.a()
结果为:
我是D里面的d方法
我是C里面的c方法
我是A里面的a方法super()重写
class Animal():
def __init__(self,name,food):
self.name = name
self.food = food
def eat(self):
print('%s喜欢吃%s'%(self.name,self.food))
def shout(self):
print(self.name,'喵喵')
#编写一个Dog类继承Animal
class Dog(Animal):
def __init__(self,name,food):
super().__init__(name,food)
def shout(self): #重写父类的shout方法,喵喵叫不适合dog的实际情况
print(self.name,'汪汪')
#编写一个Cat类继承Animal
class Cat(Animal):
def __init__(self,name,food):
super().__init__(name,food)
#对于Dog和Cat来说Animal是他们的父类,而Dog和Cat是Animal的子类。
#子类获得了父类的全部功能,自动拥有了父类的eat()方法
dog = Dog('小狗','骨头')
dog.shout()
结果为:
小狗 汪汪类方法用@classmethod装饰器来表示
类方法可以被类和对象一起访问,而对象方法只可以被对象方法访问
class Dog(object):
tooth = 10 #定义一个类属性
@classmethod #装饰器,添加其他的功能:让对象方法变成类方法
def info_print(self):
print(1)
@classmethod
def info_print1(cls): #cls表示类本身
#在方法里面去使用类本身去调用方法时可以直接使用cls
print(cls.tooth)
wangcai = Dog()
wangcai.info_print() #类方法
Dog.info_print()
Dog.info_print1() #10,用类去调用类属性得到的属性值
结果为:
1
1
10静态方法
去掉不需要的参数传递,有利于减少不必要的内存占用和性能消耗
静态方法是可以被类和对象一起访问的
class Dog(object):
@staticmethod
def info_print(): #小括号中没有self,也没有cls
print("这是一个静态方法!")
wangcai = Dog()
wangcai.info_print()
Dog.info_print()
结果为:
这是一个静态方法!
这是一个静态方法!循环语句
循环语句就是在符合条件的情况下,重复执行一个代码段,python中的循环语句有while和for。
一、while循环
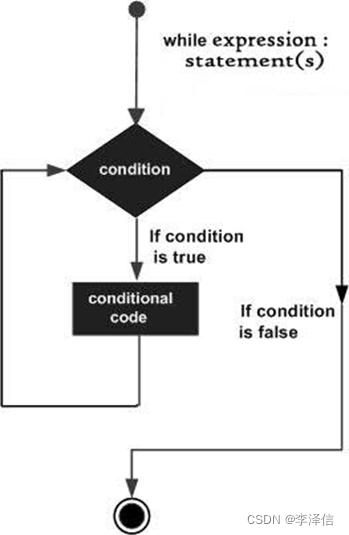
1.while是一个条件循环语句,与if一样,他也有条件表达式。如果条件为真,while中的代码就会一直循环执行,直到循环条件不再为真停止。
语法:
while 条件:
代码块例如:计算1到100的和
i = 1 #初始化一个变量
m = 0
while i <= 100:
m += i
i += 1
print(m)
结果为:50502.while循环嵌套
if中可以在嵌套if,那么while中也可以嵌套while循环,从而实行一些特殊的效果。
语句:
while 条件1:
满足条件1执行代码块1
while 条件2:
满足条件1又满足条件2执行代码块2例如:用while输出以下三角形
*
* *
* * *
* * * *
* * * * *
i = 0
while i < 5:
m = 0
while m <= i:
print('*',end=' ')
m += 1
i += 1
print()3.while循环使用else语句
while-else在条件语句为False时执行else语句块
语法:
while 条件:
满足条件执行代码块
else:
不满足条件执行代码块例如:
a = 0 #初始化变量
while a < 5:
print('好好学习!')
a += 1 #进行累加,每次循环进行加1
else:
print('不,你不学!')
结果为:
好好学习!
好好学习!
好好学习!
好好学习!
好好学习!
不,你不学!4.break
break:在循环体内遇到break则会跳出循环,终止循环,并且不论循环的条件是否为真,都不再继续循环。
例如:让用户控制循环条件,是否退出程序?(y/n)
while True: #给个条件为True
flag = input('是否要退出程序?(y/n)')
print(flag)
if flag == 'y':
break
结果为:
你是否要退出程序(y/n):y
y5.continue
continue:退出当前循环,再继续执行下一次循环。
例如:
n = 0
while n < 5:
n += 1
if n == 3:
continue
print(n)
结果为:
1
2
4
5二、for循环
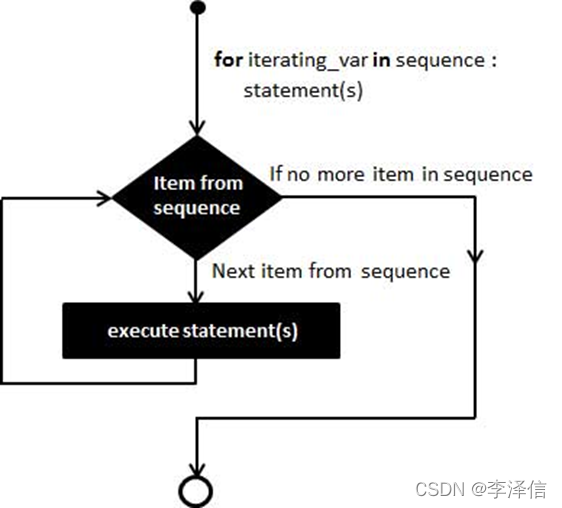
1.for 循环是python中的另外一种循环语句,提供了python中最强大的循环结构,它可以循环遍历多种序列项目,如一个列表或者一个字符串(sequence可以试列表元组集合,如果是字典只能遍历keys,无法遍历values)
语法:
for <variable> in <sequence>:
<statements>
else:
<statements>例如:
list01 = ['joe','susan','jack','tom']
for i in list01: #遍历list01列表,将列表中元素依次赋值给变量i
print(i) #输出i直到将所有的元素遍历完毕停止遍历
结果为:
joe
susan
jack
Tom2.for循环结合break使用
例如:
students = ['jack','tom','john','amy','kim','sunny']
for i in statuents:
if i == 'amy':
print('break终止循环')
break
print(i)
结果为:
jack
tom
john
break终止循环3.for循环结合continue使用
students = ['jack','tom','john','amy','kim','sunny']
for i in students:
if i == 'amy':
print('continue终止当前循环,继续下一循环')
continue
print(i)
结果为:
jack
tom
john
continue终止当前循环,继续下一循环
kim
sunny三、pass
pass语句的使用表示不希望任何代码或者命令的执行;
pass语句是一个空操作,在执行的时候不会产生任何反应;
pass语句常出现在if、while、for等各种判断或者循环语句中;
条件判断
条件语句是通过一条或者多条语句执行的结果(True或False)来决定执行的代码块
一、if条件语句
1.if 条件语句的语法:
if 条件:
执行的代码块1
elif:
执行的代码快2
else:
执行的代码块32.if中常用的操作运算符:
比较运算符:返回都是布尔值
| 运算符 | 名称 | 实例 |
|---|---|---|
| > | 大于 | x > y |
| < | 小于 | x < y |
| == | 等于 | x == y |
| >= | 大于等于 | x >= y |
| <= | 小于等于 | x <= y |
| != | 不等于 | x != y |
算术运算符
| 运算符 | 名称 | 实例 |
|---|---|---|
| + | 加法 | x + y |
| - | 减法 | x - y |
| * | 乘法 | x * y |
| / | 除法 | x / y |
| // | 取整 | x // y |
| % | 取余(取模) | x % y |
| ** | 幂 | x ** y |
赋值运算符
| 运算符 | 实例 |
|---|---|
| = | x = 5 |
| += | x += 5 |
| -= | x -= 5 |
| *= | x *= 5 |
| /= | x /= 5 |
| %= | x %= 5 |
| //= | x //= 5 |
| **= | x **= 5 |
逻辑运算符:结果都是布尔值,要么是False,要么是True
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | 如果两个语句都为真,则为真(True) | x > 3 and x < 5 |
| or | 如果其中一个语句为真,则为真(True) | x > 3 or x <4 |
| not | 反转,如果结果为真,则返回假(False) | not(x >3 and x < 5) |
成员运算符:判断是否存在
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果对象存在指定值的序列,则返回True | x in y |
| not in | 如果对象不存在指定值的序列,则返回True | x not in y |
位运算符:主要用于(二进制)数字中
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | and | 如果两个位均为1,则将每个为设为1 |
| I | or | 如果两位中的一位为1,则将每个位设为1 |
| ^ | xor | 如果两个位中只有一位为1,则将每个位设为1 |
| ~ | not | 反转所有位 |
| << | zero filll left shift | 通过从右侧推入零来向左移动,推掉最左边的位 |
| >> | signed right shift | 通过从左侧推入最左边的位的副本向右移动,推掉最右边的位 |
例如:年龄超过18才能上网,不超过18不能上网;
age = input('请输入你的年龄:')
if age >= '18': #input接收到的数据类型都是字符串,需要数据转换
print('快快乐乐的上网去了...')
else: #else后面不跟条件
print('你的年龄还小,不能上网!')3.if嵌套语句的语法:
if 条件1:
条件1执行的代码1
条件1执行的代码2
...
if 条件2:
条件2执行的代码1
条件2执行的代码2
...
elif 条件3:
条件3执行的代码块1
条件3执行的代码块2
elif 条件4:
条件4执行的代码块1
条件4执行的代码块2
else:
执行的代码块
例如:用户输入的用户名和密码判断是否可以正常登陆
name = input("请输入你的用户名:")
if name == '老王':
print('用户名输入正确,请输入密码!')
password = int(input("请输入你的密码:"))
if password == 123:
print('密码输入正确,可以登录')
else:
print('密码输入错误,请重新登录!')
else:
print('用户名输入错误,请重新输入!')3.多重判断
if 条件1:
条件1执行的代码块1
条件1执行的代码块2
...
elif 条件2:
条件2执行的代码块1
条件2执行的代码块2
...
else:
执行的代码块例如:根据用户输入的年龄判断用户所属用户年龄区间
age = int(input('请输入你的年龄'))
if age < 18:
print(f"你的年龄是{age},为童工!")
elif 18 <= age <=60:
print(f"你的年是{age},属于合法工作年龄!")
elif 60 < age <= 100:
print(f"你的年龄为{age},属于退休年龄!")
else:
print(f"你的年龄为{age},超百龄了,搁家里休息吧,别乱跑了!")集合
集合
1.集合的格式{数据1,数据2,数据3,...}
例:
s1 = {10,20,30,40}
print(type(s1)) #set类型
返回结果:
<class 'set'>2.定义空集合,注意:只能用set()
s2 = set()
print(s2)
返回结果:
set()3.集合的特点:无序和去重
s3 = {10,20,10,40,20}
print(s3) #集合中的数值不重复,去重
返回结果:
{40, 10, 20}4.集合的常用操作
增加
集合名.add(数据):数据不能是序列,是序列就会报错(不报错字符串)
#例如:
s1 = {10,20}
s1.add(30)
print(s1)
返回结果:
{10, 20, 30}
#例如:
s1 = {10,20}
s1.add([12,13]) #报错
print(s1)
返回结果:
TypeError: unhashable type: 'list'集合名.update(序列)
#例如:
s1 = {10,20}
s1.update([12,13]) #序列是逐一添加
print(s1)
返回结果:
{10, 13, 20, 12}
#例如:
s1 = {10,20}
s1.update(30) #报错,单个数据不能添加
print(s1)
返回结果:
TypeError: 'int' object is not iterable删除
集合名.remove:删除指定数据
#例如:
s2 = {10,20,30,40}
s2.remove(30) #{40, 10, 20},删除指定数据
print(s2)
返回结果:
{40, 10, 20}
#例如:
s2 = {10,20,30,40}
s2.remove(50) #删除不存在的数据会报错
print(s2)
返回结果:
KeyError: 50集合名.discard():删除指定数据
#例如:
s2 = {10,20,30,40}
s2.discard(30) #{40, 10, 20},删除指定数据
print(s2)
返回结果:
{40, 10, 20}
#例如:
s2 = {10,20,30,40}
s2.discard(50) #删除不存在的数据,不会报错
print(s2)
返回结果:
{40, 10, 20, 30}集合名.pop()
#例如:
s2 = {10,20,30,40}
del_num = s2.pop() #返回被删除的数据
print(del_num) #40,随机删除,因为集合的无序特点,默认删除集合中的第一个数据
print(s2)
返回结果:
40
{10, 20, 30}查找:in 和 not in
s3 = {10,20,30,40}
#in:存在则返回True,不存在则返回False
print(30 in s3) #存在则返回True
print(50 in s3) #不存在则返回False
#not in:存在则返回False,不存在则返回True
print(30 not in s3) #存在则返回False
print(50 not in s3) #不存在则返回True
返回结果:
True
False
False
True-
1 2

