异常
异常
python遇到错误后,会引发异常。如果异常对象并未被处理或捕捉,则程序就会用所谓的晦朔(Traceback,一种错误信息)来终止执行。
处理异常
1.异常是指在程序执行过程中发生的一个时间,会影响程序的正常运行,所以一般需要进行捕获异常处理。
2.异常的捕获使用try/except/finally语句进行捕获操作,并告诉python发生异常时怎么。
语法:
try:
<语句>
except <异常类型1>[, 异常参数名1]:
<异常处理代码1>
except <异常类型2>[, 异常参数名2]:
<异常处理代码2>
else:
<没有异常时候的处理代码>
finally:
<不管是否有异常,最终执行的代码块>例如:
try:
print(aaa) #如果这句话有错,就会捕获到异常
except NameError: #NameError异常
print('变量未定义') #对NameError异常的处理
结果为:
变量为定义捕获异常的具体信息
例如:
try:
print(aaa) #如果这句话有错,就会捕获到异常
except NameError as e:
print(e) #打印具体的异常信息
print('变量未定义')
结果为:
name 'aaa' is not defined
变量未定义包含多个异常
例如:
try:
# print(aaa)
files = open('aaa.txt','r',encoding='utf-8') #如果这句话有错,就会捕获到异常
except (NameError,FileNotFoundError) as e:
print(e) #打印具体的异常信息万能方法Exception
例如:
try:
files = open('aaa.txt','r',encoding='utf-8') #如果这句话有错,就会捕获到异常
except Exception as e:
print(e)else:没有异常时要执行的语句
例如:
try:
files = open('aaa.txt','r',encoding='utf-8') #如果这句话有错,就会捕获到异常
except Exception as e: #有异常时执行
print(e)
else: #没有异常时执行
print('没什么问题')
结果为:
没什么问题finally:不管有没有异常都会执行的代码块
例如:
try:
print("打开文件!")
files = open('aaa.txt','w',encoding='utf-8')
try:
files.write('测试下行不行')
except:
print('写入失败!')
else:
print('写入成功!')
finally:
print('关闭文件!')
files.close()
except Exception as e:
print(e)
结果为:
打开文件!
写入成功!
关闭文件!例如:
加法运算:提示用户提供数值输入时,常出现的一个问题是,用户提供的是文本而不是数字。
在这种情况下,当你尝试将输入转换为整数时,将引发TypeError 异常。编写一个程序,
提示用户输入两个数字,再将它们相加并打印结果。在用户输入的任何一个值不是数字时都捕获TypeError 异常,
并打印一条友好的错误消息。对你编写的程序进行测试:先输入两个数字,再输入一些文本而不是数字。
try:
num1 = int(input('请输入第一个数字:'))
num2 = int(input('请输入第二个数字:'))
except ValueError:
print('请输入一个整数')
else:
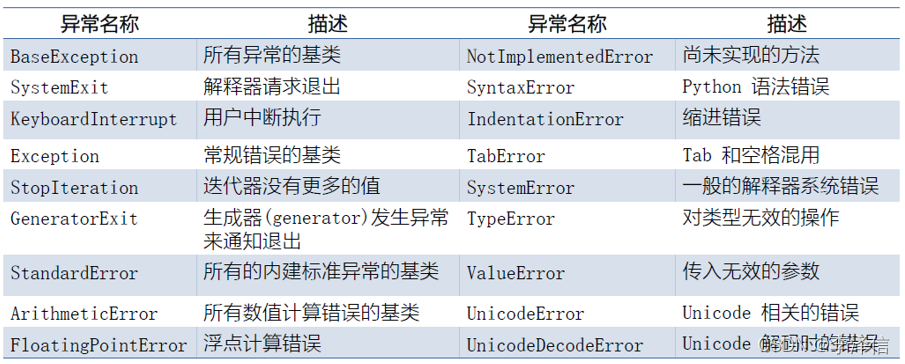
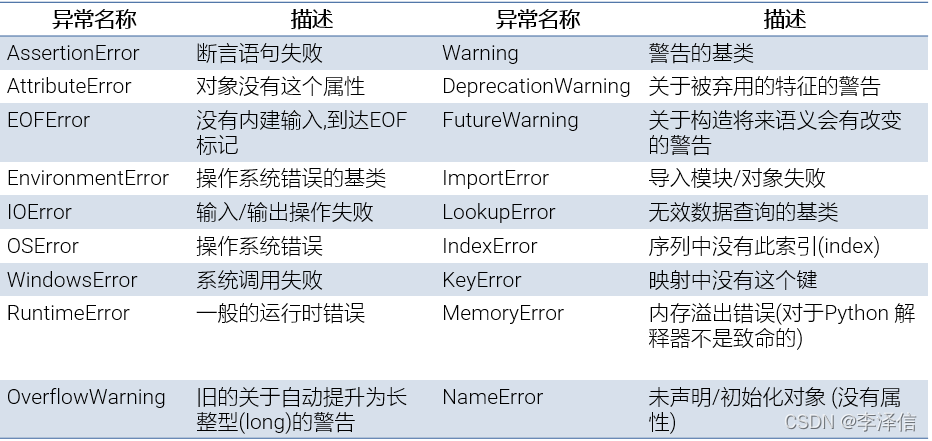
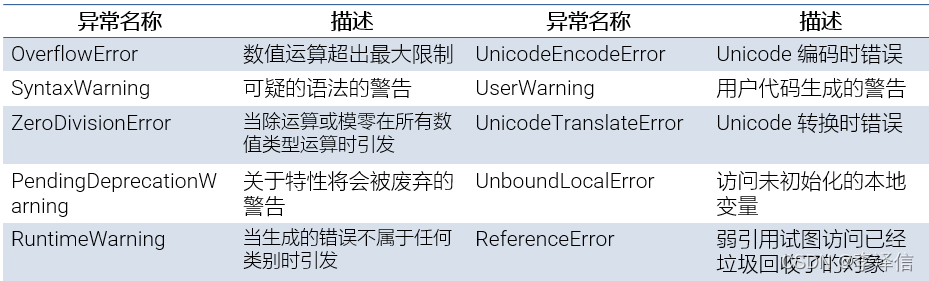
print(num1 + num2)常出现异常类型
文件的操作
open函数
语法:
open(name[,mode[,bufferning[,encoding]]])
name:包含了要访问的文件名称的字符串值[区分绝对路径和相对路径]
mode:决定了打开文件的模式:只读,写入,追加等。
buffering:如果buffering的值被设置为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果buffering的值设置为大于1的整数,表明了是寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。关闭文件
语法:
文件对象.close()
例如:
file = open('1.txt,'w')
file.close()文件读写
read(num):可以读取文件里面的内容。num表示要从文件读取的数据长度(单位是字节),如果没有传入num,那么表示读取文件中所有的数据
语法:
read(num)
例如:
#读取操作
f = open('test.txt','r')
content = f.read(5)
print(content)
print('_'*30)
content = f.read()
print(content)
f.close()
结果为:
1
2
3
______________________________
4
5
6
7
open文件
用open结合for循环逐行读取
files = open('python.txt','r',encoding='utf-8')
i = 1
for line in files:
# 没有使用read
print('这是第%d行内容:%s'%(i,line),end='')
i += 1
files.close()
结果为:
这是第1行内容:123456789
这是第2行内容:SADFASDFwith...open
关键字with在不在需要访问文件后将其关闭。可以让python去确定:你只管打开文件,并在需要时使用它,python自会在合适的时候自动将其关闭;
也可以使用open()和close()来打开和关闭文件,但这样做,如果程序存在bug,导致close()语句未执行,文件将不会关闭。
#用with结合for
with open('python.txt','r',encoding='utf-8') as files:
i = 1
for line in files:
print('这是第%d行内容:%s'%(i,line),end='')
i += 1
结果为:
这是第1行内容:123456789
这是第2行内容:SADFASDF访问模式


文件的读
readlines:可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
语法:
readlines()
例如:用open与for循环进行逐行读取
f = open('test.txt','r',encoding='utf-8')
content = f.readlines()
i = 1
for list1 in content:
print('这是第%d行内容:%s'%(i,list1),end='')
i += 1
f.close()
结果为:
这是第1行内容:1
这是第2行内容:2
这是第3行内容:3
这是第4行内容:4
这是第5行内容:5
这是第6行内容:6
这是第7行内容:7
例如:用with与for循环进行逐行读取
with open('test.txt','r',encoding='utf-8') as files:
contents = files.readlines()
i = 1
for list1 in contents:
print('这是第%d行内容:%s'%(i,list1),end='')
i += 1
结果为:
这是第1行内容:1
这是第2行内容:2
这是第3行内容:3
这是第4行内容:4
这是第5行内容:5
这是第6行内容:6
这是第7行内容:7写入文件
1.如果要写入的文件不存在,函数open()将自动创建。
2.使用文件对象的访问write()讲一个字符串写入文件,这个程序是没有终端输出
3.函数write()不会再写入的文本末尾添加换行符,需要手动添加\n
注意:python只能将字符串写入文本文件,要将数值数据存储到文本文件中,必须先使用函数str()将其转换为字符串格式。
例如:
files = open('python.txt','w',encoding='utf-8')
content = 'hello world!'
content = '一起耍,可以吗??'
files.write(content) #写入数据
files.close()
例如:
with open('python.txt','a',encoding='utf-8') as files:
content = '\n滚蛋!'
files.write(content)常用函数


tell查看文件指针
例如:python.txt文件内容是:1234567890
files = open('python.txt','r',encoding='utf-8')
str = files.read(5)
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
str = files.read()
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
files.close()
结果是:
当前读取的数据是:12345
当前的位置是: 5
当前读取的数据是:67890
当前的位置是: 10seek()设置指针
例如:python.txt文件内容是:1234567890
files = open('python.txt','r',encoding='utf-8')
str = files.read(5)
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
# 重新设置文件的指针
files.seek(2,0)
str = files.read(2)
print('当前读取的数据是:' +str)
# 查看文件的指针
position = files.tell()
print('当前的位置是:',position)
files.close()
结果为:
当前读取的数据是:12345
当前的位置是: 5
当前读取的数据是:34
当前的位置是: 4面向对象
面向对象:
面向对象就不像面向过程那样按照功能划分模块了,它所关注的是软件系统有哪些参与者,把这些参与者称为对象,找出这些软件系统的参与者也就是对象之后,分析这些对象有哪些特征、哪些行为,以及对象之间的关系,所以说面向对象的开发核心是对象
类
类是对象的类型,具有相同属性和行为事物的统称。类是抽象的,在使用的时候通常会找到这个类的一个具体存在
对象
万物皆对象,对象拥有自己的特征和行为。
类和对象的关系
类是对象的类型,对象是类的实例。类是抽象的概念,而对象是一个你能够摸得着,看得到的实体。二者相辅相成,谁也离不开谁
创建和使用类
定义类:
class 类名():
#文档说明
属性
方法
注意:类名要满足标识符命名规则,同时要遵循大驼峰命名习惯
例如:
class Person():
'''这是一个人类'''
country = '中国' #声明类属性,并且赋值
#实例属性同构造方法来声明
#self不是关键字,代表的是当前对象
def __init__(self,name,age,sex): #构造方法
#构造方法不需要调用,在实例化的时候自动调用
self.name = name
self.age = age
self.sex = sex
#创建普通方法
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}') #在方法里面使用实例属性
#实例化对象
people01 = Person('joe',18,'男') #在实例化的时候传参
#通过对象调用实例方法
people01.getName()
结果为:
我的名字叫:joe,年龄是:18,性别是:男,我来自:中国类的属性分类

访问属性
class Person():
country = '中国'
def __init__(self,name,age,sex):
self.name =name
self.age = age
self.sex = sex
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}')
people01 = Person('joe',18,'男')
print(people01.name) #通过对象名.属性名,访问实例属性(对象属性)
print(people01.age)
print(people01.sex)
结果为:
joe
18
男针对类的属性的一些方法
可以使用点实例化对象名+.来访问对象的属性,也可以使用以下函数的方式来访问属性
class Person():
country = '中国'
def __init__(self,name,age,sex):
self.name =name
self.age = age
self.sex = sex
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}')
people01 = Person('joe',18,'男')
1.访问对象的属性 getattr(obj, name[, default])
print(getattr(people01,'name'))
结果为:
joe
2.检查是否存在一个属性hasattr(obj,name),存在为True,不存在为False
print(hasattr(people01,'name'))
结果为:
True
3.设置一个属性setattr(obj,name,value) 。如果属性不存在,会创建一个新属性
print(setattr(people01,'name','susan')) #不存在返回None
print(people01.name)
结果为:
None
susan
4.删除属性delattr(obj, name)
delattr(people01,'name')
print(people01.name) #在此print执行会报错
注意:name需要加单引号,obj为实例化对象名称内置属性
class Person():
country = '中国'
def __init__(self,name,age,sex):
self.name =name
self.age = age
self.sex = sex
def getName(self):
print(f'我的名字叫:{self.name},年龄是:{self.age},性别是:{self.sex},我来自:{Person.country}')
people01 = Person('joe',18,'男')
1.__dict__ : 类的属性(包含一个字典,由类的属性名:值组成) 实例化类名.__dict__
print(people01.__dict__)
结果为:
{'name': 'joe', 'age': 18, 'sex': '男'}
2.__doc__ :类的文档字符串 (类名.)实例化类名.__doc__
print(people01.__doc__)
结果为:
这是一个人类
3.__name__: 类名,实现方式 类名.__name__
print(Person.__name__)
结果为:
Person
4.__bases__ : 类的所有父类构成元素(包含了以个由所有父类组成的元组)
print(Person.__bases__)
结果为:
(<class 'object'>,)init ()构造方法和self
init ()是一个特殊的方法属于类的专有方法,被称为类的构造函数或初始化方法,方法的前面和后面都有两个下划线。
这是为了避免Python默认方法和普通方法名称的冲突。每当创建类的实例化对象的时候, init ()方法都会默认被运行。作用就是初始化已实例化后的对象。
在方法定义中,第一个参数self是必不可少的。类的方法和普通的函数的区别就是self,self并不是Python的关键字,只是按照惯例和标准的规定,推荐使用self。
name
name :如果放在Modules模块中,表示的是模块的名字,如果放在class类中,表示的是类的名字
main :模块,xxx.py文件本身被直接执行时,对应的模块名就是 main _ 了
可以在 if name == " main _":中添加自己想要的,用于测试模块,演示模块用法等代码作为模块,被别的Python程序导入时,模块名就是本身文件名了。
继承
程序中定义一个class的时候,可以从某个现有的class继承,新的class成为子类(Subclass),而被继承的class称之为基类、父类或超类。子类继承了其父类所有属性和方法,同事还可以定义自己的属性和方法。
例如:
#声明一个父类
class Animal():
def __init__(self,name,food):
self.name = name
self.food = food
def eat(self):
print('%s爱吃%s'%(self.name,self.food))
#声明一个子类继承Animal
class Dog(Animal):
def __init__(self,name,food,drink):
super(Dog,self).__init__(name,food)
#子类自己的属性
self.drink = drink
#子类自己的方法
def drinks(self):
print('%s爱吃%s'(self.name,self.food,self.drink))
class Cat(Animal):
def __init__(self,name,food,drink):
super(Cat,self).__init__(name,food)
#子类自己的属性
self.drink = drink
#子类自己的方法
def drinks(self):
print(f'%s爱吃%s'(self.name,self.food,self.drink))
#重写父类的eat
def eat(self):
print('%s特别爱吃%s'%(self.name,self.food))
dog1 = Dog('金毛','骨头','可乐')
dog1.eat()
dog1.drinks()
cat1 = Cat('波斯猫','鱼','雪碧')
cat1.eat()
cat1.drinks()
结果为:
金毛爱吃骨头
金毛爱喝可乐
波斯猫特别爱吃鱼
波斯猫爱喝雪碧多继承
语法格式如下:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
注意:圆括号中父类的顺序,如果继承的父类中有相同的方法名,而在子类中使用时未指定,python将从左到右查找父类中是否包含方法class A():
def a(self):
print('我是A里面的a方法')
class B():
def b(self):
print('我是B里面的b方法')
def a(self):
print('我是B里面的a方法')
class C():
def c(self):
print('我是C里面的c方法')
class D(A,B,C):
def d(self):
print('我是D里面的d方法')
dd = D()
dd.d() #调用自己的方法
dd.c()
dd.a()
结果为:
我是D里面的d方法
我是C里面的c方法
我是A里面的a方法super()重写
class Animal():
def __init__(self,name,food):
self.name = name
self.food = food
def eat(self):
print('%s喜欢吃%s'%(self.name,self.food))
def shout(self):
print(self.name,'喵喵')
#编写一个Dog类继承Animal
class Dog(Animal):
def __init__(self,name,food):
super().__init__(name,food)
def shout(self): #重写父类的shout方法,喵喵叫不适合dog的实际情况
print(self.name,'汪汪')
#编写一个Cat类继承Animal
class Cat(Animal):
def __init__(self,name,food):
super().__init__(name,food)
#对于Dog和Cat来说Animal是他们的父类,而Dog和Cat是Animal的子类。
#子类获得了父类的全部功能,自动拥有了父类的eat()方法
dog = Dog('小狗','骨头')
dog.shout()
结果为:
小狗 汪汪类方法用@classmethod装饰器来表示
类方法可以被类和对象一起访问,而对象方法只可以被对象方法访问
class Dog(object):
tooth = 10 #定义一个类属性
@classmethod #装饰器,添加其他的功能:让对象方法变成类方法
def info_print(self):
print(1)
@classmethod
def info_print1(cls): #cls表示类本身
#在方法里面去使用类本身去调用方法时可以直接使用cls
print(cls.tooth)
wangcai = Dog()
wangcai.info_print() #类方法
Dog.info_print()
Dog.info_print1() #10,用类去调用类属性得到的属性值
结果为:
1
1
10静态方法
去掉不需要的参数传递,有利于减少不必要的内存占用和性能消耗
静态方法是可以被类和对象一起访问的
class Dog(object):
@staticmethod
def info_print(): #小括号中没有self,也没有cls
print("这是一个静态方法!")
wangcai = Dog()
wangcai.info_print()
Dog.info_print()
结果为:
这是一个静态方法!
这是一个静态方法!循环语句
循环语句就是在符合条件的情况下,重复执行一个代码段,python中的循环语句有while和for。
一、while循环
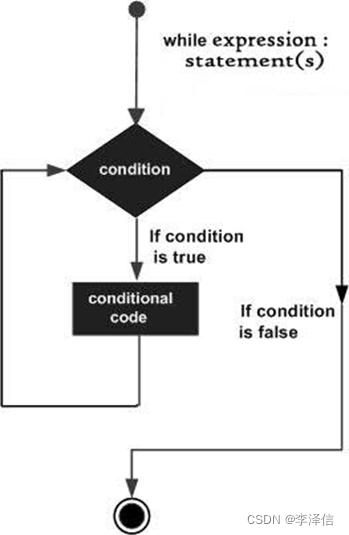
1.while是一个条件循环语句,与if一样,他也有条件表达式。如果条件为真,while中的代码就会一直循环执行,直到循环条件不再为真停止。
语法:
while 条件:
代码块例如:计算1到100的和
i = 1 #初始化一个变量
m = 0
while i <= 100:
m += i
i += 1
print(m)
结果为:50502.while循环嵌套
if中可以在嵌套if,那么while中也可以嵌套while循环,从而实行一些特殊的效果。
语句:
while 条件1:
满足条件1执行代码块1
while 条件2:
满足条件1又满足条件2执行代码块2例如:用while输出以下三角形
*
* *
* * *
* * * *
* * * * *
i = 0
while i < 5:
m = 0
while m <= i:
print('*',end=' ')
m += 1
i += 1
print()3.while循环使用else语句
while-else在条件语句为False时执行else语句块
语法:
while 条件:
满足条件执行代码块
else:
不满足条件执行代码块例如:
a = 0 #初始化变量
while a < 5:
print('好好学习!')
a += 1 #进行累加,每次循环进行加1
else:
print('不,你不学!')
结果为:
好好学习!
好好学习!
好好学习!
好好学习!
好好学习!
不,你不学!4.break
break:在循环体内遇到break则会跳出循环,终止循环,并且不论循环的条件是否为真,都不再继续循环。
例如:让用户控制循环条件,是否退出程序?(y/n)
while True: #给个条件为True
flag = input('是否要退出程序?(y/n)')
print(flag)
if flag == 'y':
break
结果为:
你是否要退出程序(y/n):y
y5.continue
continue:退出当前循环,再继续执行下一次循环。
例如:
n = 0
while n < 5:
n += 1
if n == 3:
continue
print(n)
结果为:
1
2
4
5二、for循环
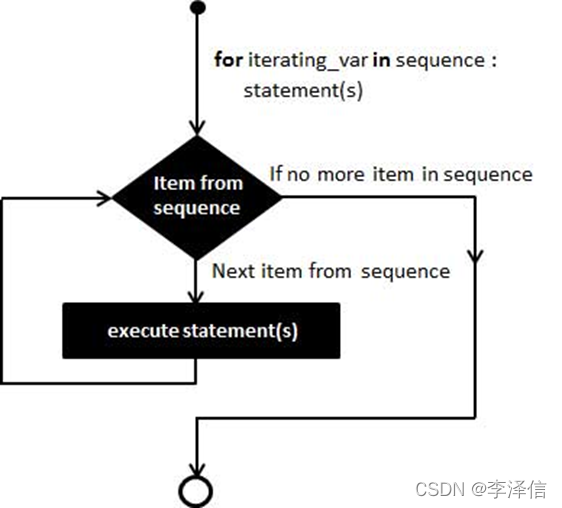
1.for 循环是python中的另外一种循环语句,提供了python中最强大的循环结构,它可以循环遍历多种序列项目,如一个列表或者一个字符串(sequence可以试列表元组集合,如果是字典只能遍历keys,无法遍历values)
语法:
for <variable> in <sequence>:
<statements>
else:
<statements>例如:
list01 = ['joe','susan','jack','tom']
for i in list01: #遍历list01列表,将列表中元素依次赋值给变量i
print(i) #输出i直到将所有的元素遍历完毕停止遍历
结果为:
joe
susan
jack
Tom2.for循环结合break使用
例如:
students = ['jack','tom','john','amy','kim','sunny']
for i in statuents:
if i == 'amy':
print('break终止循环')
break
print(i)
结果为:
jack
tom
john
break终止循环3.for循环结合continue使用
students = ['jack','tom','john','amy','kim','sunny']
for i in students:
if i == 'amy':
print('continue终止当前循环,继续下一循环')
continue
print(i)
结果为:
jack
tom
john
continue终止当前循环,继续下一循环
kim
sunny三、pass
pass语句的使用表示不希望任何代码或者命令的执行;
pass语句是一个空操作,在执行的时候不会产生任何反应;
pass语句常出现在if、while、for等各种判断或者循环语句中;
条件判断
条件语句是通过一条或者多条语句执行的结果(True或False)来决定执行的代码块
一、if条件语句
1.if 条件语句的语法:
if 条件:
执行的代码块1
elif:
执行的代码快2
else:
执行的代码块32.if中常用的操作运算符:
比较运算符:返回都是布尔值
| 运算符 | 名称 | 实例 |
|---|---|---|
| > | 大于 | x > y |
| < | 小于 | x < y |
| == | 等于 | x == y |
| >= | 大于等于 | x >= y |
| <= | 小于等于 | x <= y |
| != | 不等于 | x != y |
算术运算符
| 运算符 | 名称 | 实例 |
|---|---|---|
| + | 加法 | x + y |
| - | 减法 | x - y |
| * | 乘法 | x * y |
| / | 除法 | x / y |
| // | 取整 | x // y |
| % | 取余(取模) | x % y |
| ** | 幂 | x ** y |
赋值运算符
| 运算符 | 实例 |
|---|---|
| = | x = 5 |
| += | x += 5 |
| -= | x -= 5 |
| *= | x *= 5 |
| /= | x /= 5 |
| %= | x %= 5 |
| //= | x //= 5 |
| **= | x **= 5 |
逻辑运算符:结果都是布尔值,要么是False,要么是True
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | 如果两个语句都为真,则为真(True) | x > 3 and x < 5 |
| or | 如果其中一个语句为真,则为真(True) | x > 3 or x <4 |
| not | 反转,如果结果为真,则返回假(False) | not(x >3 and x < 5) |
成员运算符:判断是否存在
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果对象存在指定值的序列,则返回True | x in y |
| not in | 如果对象不存在指定值的序列,则返回True | x not in y |
位运算符:主要用于(二进制)数字中
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | and | 如果两个位均为1,则将每个为设为1 |
| I | or | 如果两位中的一位为1,则将每个位设为1 |
| ^ | xor | 如果两个位中只有一位为1,则将每个位设为1 |
| ~ | not | 反转所有位 |
| << | zero filll left shift | 通过从右侧推入零来向左移动,推掉最左边的位 |
| >> | signed right shift | 通过从左侧推入最左边的位的副本向右移动,推掉最右边的位 |
例如:年龄超过18才能上网,不超过18不能上网;
age = input('请输入你的年龄:')
if age >= '18': #input接收到的数据类型都是字符串,需要数据转换
print('快快乐乐的上网去了...')
else: #else后面不跟条件
print('你的年龄还小,不能上网!')3.if嵌套语句的语法:
if 条件1:
条件1执行的代码1
条件1执行的代码2
...
if 条件2:
条件2执行的代码1
条件2执行的代码2
...
elif 条件3:
条件3执行的代码块1
条件3执行的代码块2
elif 条件4:
条件4执行的代码块1
条件4执行的代码块2
else:
执行的代码块
例如:用户输入的用户名和密码判断是否可以正常登陆
name = input("请输入你的用户名:")
if name == '老王':
print('用户名输入正确,请输入密码!')
password = int(input("请输入你的密码:"))
if password == 123:
print('密码输入正确,可以登录')
else:
print('密码输入错误,请重新登录!')
else:
print('用户名输入错误,请重新输入!')3.多重判断
if 条件1:
条件1执行的代码块1
条件1执行的代码块2
...
elif 条件2:
条件2执行的代码块1
条件2执行的代码块2
...
else:
执行的代码块例如:根据用户输入的年龄判断用户所属用户年龄区间
age = int(input('请输入你的年龄'))
if age < 18:
print(f"你的年龄是{age},为童工!")
elif 18 <= age <=60:
print(f"你的年是{age},属于合法工作年龄!")
elif 60 < age <= 100:
print(f"你的年龄为{age},属于退休年龄!")
else:
print(f"你的年龄为{age},超百龄了,搁家里休息吧,别乱跑了!")集合
集合
1.集合的格式{数据1,数据2,数据3,...}
例:
s1 = {10,20,30,40}
print(type(s1)) #set类型
返回结果:
<class 'set'>2.定义空集合,注意:只能用set()
s2 = set()
print(s2)
返回结果:
set()3.集合的特点:无序和去重
s3 = {10,20,10,40,20}
print(s3) #集合中的数值不重复,去重
返回结果:
{40, 10, 20}4.集合的常用操作
增加
集合名.add(数据):数据不能是序列,是序列就会报错(不报错字符串)
#例如:
s1 = {10,20}
s1.add(30)
print(s1)
返回结果:
{10, 20, 30}
#例如:
s1 = {10,20}
s1.add([12,13]) #报错
print(s1)
返回结果:
TypeError: unhashable type: 'list'集合名.update(序列)
#例如:
s1 = {10,20}
s1.update([12,13]) #序列是逐一添加
print(s1)
返回结果:
{10, 13, 20, 12}
#例如:
s1 = {10,20}
s1.update(30) #报错,单个数据不能添加
print(s1)
返回结果:
TypeError: 'int' object is not iterable删除
集合名.remove:删除指定数据
#例如:
s2 = {10,20,30,40}
s2.remove(30) #{40, 10, 20},删除指定数据
print(s2)
返回结果:
{40, 10, 20}
#例如:
s2 = {10,20,30,40}
s2.remove(50) #删除不存在的数据会报错
print(s2)
返回结果:
KeyError: 50集合名.discard():删除指定数据
#例如:
s2 = {10,20,30,40}
s2.discard(30) #{40, 10, 20},删除指定数据
print(s2)
返回结果:
{40, 10, 20}
#例如:
s2 = {10,20,30,40}
s2.discard(50) #删除不存在的数据,不会报错
print(s2)
返回结果:
{40, 10, 20, 30}集合名.pop()
#例如:
s2 = {10,20,30,40}
del_num = s2.pop() #返回被删除的数据
print(del_num) #40,随机删除,因为集合的无序特点,默认删除集合中的第一个数据
print(s2)
返回结果:
40
{10, 20, 30}查找:in 和 not in
s3 = {10,20,30,40}
#in:存在则返回True,不存在则返回False
print(30 in s3) #存在则返回True
print(50 in s3) #不存在则返回False
#not in:存在则返回False,不存在则返回True
print(30 not in s3) #存在则返回False
print(50 not in s3) #不存在则返回True
返回结果:
True
False
False
True
