Tomcat讲解及安装
一、认识Tomcat
-
概述
Tomcat是由Apache软件基金会下属的Jakarta项目开发的一个Servlet容器,按照Sun Microsystems提供的技术规范,实现了对Servlet和JavaServer Page(JSP)的支持,并提供了作为Web服务器的一些特有功能,如Tomcat管理和控制平台、安全域管理和Tomcat阀等。由于Tomcat本身也内含了一个HTTP服务器,它也可以被视作一个单独的Web服务器。 -
Java程序开发流程
开发人员windows主机--jdk--开发工具--开发代码--开发程序
后缀是.java的代码文件--java命令来编译(jdk提供的,环境)--.class文件---
刚才.java文件和.class文件 后端文件
被用户所访问的是前端文件.jsp文件(html文件)--调用后端的.class文件--
开发人员呈献给运维人员的文件.jsp和.class文件
运维人员将上述文件传到tomcat服务器
客户端http协议访问--.jsp文件
.jar包(由来:是由.java文件编译而来,编译的同时,将.java文件--.class文件--打包成.jar包)
比如说在一个.jsp文件里需要使用当前系统时间十次
输出时间的代码得写十遍--.java--.clss(十行)--十遍--一百行--麻烦
输出时间的代码得写十遍--调用输出时间的.jar包--十次--即可
.war包--压缩包--将开发人员最后的项目(.jsp文件、.class文件、.jar包)--打包成为.war包
.war包--运维人员无需解压--直接传到tomcat的网站路径下--tomcat自动识别war包--自动解压 -
便于理解:Apache和Tomcat的比较
-
相同点
- 两者都是Apache住址开发的
- 两者都有HTTP服务功能
- 两者都是免费的
-
不同点
- Apache是专门用了提供HTTP服务的,以及相关配置的(例如虚拟主机、URL转发等等),而Tomcat是Apache组织在符合Java EE的JSP、Servlet标准下开发的一个JSP服务器
- Apache是一个Web服务器环境程序,启用他可以作为Web服务器使用,不过只支持静态网页。如果要在Apache环境下运行JSP的话就需要一个解释器来执行JSP网页,而这个JSP解释器就是Tomcat。
- Apache侧重于HTTPServer ,Tomcat侧重于Servlet引擎,如果以Standalone方式运行,功能上与Apache等效,支持JSP,但对静态网页不太理想
- Apache是Web服务器,Tomcat是应用(Java)服务器,它只是一个Servlet(JSP也翻译成Servlet)容器,可以认为是Apache的扩展,但是可以独立于Apache运行
-
-
Tomcat同类产品
- Resin 服务器
Resin是Caucho公司的产品,是一个非常流行的支持Servlet和JSP的服务器,速度非常快。Resin本身包含了一个支持HTML的Web服务器,这使它不仅可以显示动态内容,而且显示静态内容的能力也毫不逊色,因此许多网站都是使用Resin服务器构建。 - Jetty 服务器
Jetty是一个纯粹的基于Java的网页服务器和Java Servlet容器。尽管网页服务器通常用来为人们呈现文档,但是Jetty通常在较大的软件框架中用于计算机与计算机之间的通信。Jetty作为Eclipse基金会的一部分,是一个自由和开源项目。 - JBoss服务器
JBoss是一个种遵从JavaEE规范的、开放源代码的、纯Java的EJB服务器,对于J2EE有很好的支持。JBoss采用JML API实现软件模块的集成与管理,其核心服务又是提供EJB服务器,不包含Servlet和JSP的Web容器,不过它可以和Tomcat完美结合。 - WebSphere 服务器
WebSphere是IBM公司的产品,可进一步细分为 WebSphere Performance Pack、Cache Manager 和WebSphere Application Server等系列,其中WebSphere Application Server 是基于Java 的应用环境,可以运行于 Sun Solaris、Windows NT 等多种操作系统平台,用于建立、部署和管理Internet和Intranet Web应用程序。 - WebLogic 服务器
WebLogic 是ORACLE公司的产品,可进一步细分为 WebLogic Server、WebLogic Enterprise 和 WebLogic Portal 等系列,其中 WebLogic Server 的功能特别强大。WebLogic 支持企业级的、多层次的和完全分布式的Web应用,并且服务器的配置简单、界面友好。对于那些正在寻求能够提供Java平台所拥有的一切应用服务器的用户来说,WebLogic是一个十分理想的选择。
- Resin 服务器
二、Tomcat与jdk的关系

解析:
JDK是开发人员开发使用,jre是用来运行java程序,就是java程序的运行环境,jvm是整个java实现跨平台的最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行;
JDK中包含JRE,在JDK的安装目录下有一个名为jre的目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。jdk是java语言编写的,用来给java程序调用的,jvm因为与平台进行交互,是用c/c++和汇编语言编写的;
jdk是java运行和编译的,tomcat是web项目的运行容器,java没有jdk没办法编译运行,java运行必须依赖jdk的环境,所以安装tomcat前必须要安装jdk环境;
-
下载位置:
注解:
1. Java SE(Java Platform,Standard Edition):Java SE 是做电脑上运行的软件;
2. Java EE(Java Platform,Enterprise Edition):Java EE 是用来做网站的(我们常见的JSP技术);
3. Java ME(Java Platform,Micro Edition):Java ME 是做手机软件的;- 对应关系


三、Tomcat内部工作原理
-
tomcat整体架构

-
组件关系
- Tomcat 的心脏是两个组件:Connector 和 Container,Connector 组件是可以被替换,这样显得更加灵活,一个 Container 可以选择对应多个 Connector。多个 Connector 和一个 Container 就形成了一个 Service,有了 Service 就可以对外提供服务了,但是 Service 还要一个生存的环境,必须要有人能够给她生命、掌握其生死大权,那就非 Server 莫属了。所以整个 Tomcat 的生命周期由 Server 控制。
- 我们将 Tomcat 中 Connector、Container 作为一个整体比作一对情侣的话,Connector 主要负责对外交流,可以比作为 Boy,Container 主要处理 Connector 接受的请求,主要是处理内部事务,可以比作为 Girl。那么这个 Service 就是连接这对男女的结婚证了。是Service 将它们连接在一起,共同组成一个家庭。当然要组成一个家庭还要很多其它的元素说白了,Service 只是在 Connector 和 Container 外面多包一层,把它们组装在一起,向外面提供服务,一个 Service 可以设置多个 Connector,但是只能有一个 Container 容器。
-
Container组件详解

- Engine:负责处理所有请求,处理后,将结果返回给service,而connector是作为service与engine的中间媒介出现的。 作为交流者;一个engine下可以配置一个默认主机,每个虚拟主机都有一个域名。当engine获得一个请求时,它把该请求匹配到虚拟主机host上,然后把请求交给该主机来处理。 Engine有一个默认主机,当请求无法匹配到任何一个虚拟主机时,将交给默认host来处理。Engine以线程的方式启动Host。
- Host:代表一个虚拟主机,每个虚拟主机和某个网络域名(Domain Name)相匹配。 每个虚拟主机下都可以部署一个或多个web应用,每个web应用对应于一个context,有一个context path。 当Host获得一个请求时,将把该请求匹配到某个Context上;
-Wrapper: 代表一个 Servlet,它负责管理一个 Servlet,包括的 Servlet 的装载、初始化、执行以及资源回收。Wrapper 是最底层的容器,它没有子容器了;


四、Tomcat配置文件详解

tomcat配置文件:
server.xml: Tomcat的主配置文件,包含Service, Connector, Engine, Realm, Valve, Hosts主组件的相关配置信息;
web.xml:遵循Servlet规范标准的配置文件,用于配置servlet,并为所有的Web应用程序提供包括MIME映射等默认配置信息;
tomcat-user.xml:Realm认证时用到的相关角色、用户和密码等信息;Tomcat自带的manager默认情况下会用到此文件;在Tomcat中添加/删除用户,为用户 指定角色等将通过编辑此文件实现;
catalina.policy:Java相关的安全策略配置文件,在系统资源级别上提供访问控制的能力;
catalina.properties:Tomcat内部package的定义及访问相关控制,也包括对通过类装载器装载的内容的控制;Tomcat在启动时会事先读取此文件的相关设置;
logging.properties: Tomcat6通过自己内部实现的JAVA日志记录器来记录操作相关的日志,此文件即为日志记录器相关的配置信息,可以用来定义日志记录的组 件级别以及日志文件的存在位置等;
context.xml:所有host的默认配置信息;


tomcat中支持两种协议的连接器:HTTP/1.1与AJP/1.3
HTTP/1.1协议负责建立HTTP连接,web应用通过浏览器访问tomcat服务器用的就是这个连接器,默认监听的是8080端口;
AJP/1.3协议负责和其他HTTP服务器建立连接,监听的是8009端口,比如tomcat和apache或者iis集成时需要用到这个连接器。
- 扩展:tomcat架构以及详细配置如下;
https://www.cnblogs.com/hggen/p/6264475.html
https://blog.csdn.net/skp127/article/details/52026150
五、Tomcat安装
| 系统类型 | IP | 主机名 | 所需软件 |
|---|---|---|---|
| centos7.8 | 192.168.100.101 | localhost | apache-tomcat-9.0.10.tar.gz、 jdk-8u171-linux-x64.tar.gz |
- 安装jdk,部署java环境
[root@localhost ~]# tar xf jdk-8u171-linux-x64.tar.gz
[root@localhost ~]# mv jdk1.8.0_171/ /usr/local/java
[root@localhost ~]# ls /usr/local/java
bin COPYRIGHT db include javafx-src.zip jre lib LICENSE man README.html release src.zip THIRDPARTYLICENSEREADME-JAVAFX.txt THIRDPARTYLICENSEREADME.txt- 安装tomcat
[root@localhost ~]# tar xf apache-tomcat-9.0.10.tar.gz
[root@localhost ~]# mv apache-tomcat-9.0.10 /usr/local/tomcat
[root@localhost ~]# ls /usr/local/tomcat
bin conf lib LICENSE logs NOTICE RELEASE-NOTES RUNNING.txt temp webapps work
[root@localhost ~]# vi /usr/local/tomcat/bin/catalina.sh
#!/bin/sh
JAVA_OPTS="-Xms512m -Xmx1024m -Xss1024K -XX:PermSize=512m -XX:MaxPermSize=1024m"
export CATALINA_HOME=/usr/local/tomcat
export JRE_HOME=/usr/local/java/jre
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export TOMCAT_HOME=/usr/local/tomcat
[root@localhost ~]# /usr/local/tomcat/bin/startup.sh
Using CATALINA_BASE: /usr/local/tomcat
Using CATALINA_HOME: /usr/local/tomcat
Using CATALINA_TMPDIR: /usr/local/tomcat/temp
Using JRE_HOME: /usr/local/java
Using CLASSPATH: /usr/local/tomcat/bin/bootstrap.jar:/usr/local/tomcat/bin/tomcat-juli.jar
Tomcat started.
[root@localhost bin]# netstat -utpln |grep 80
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 1617/java
tcp 0 0 127.0.0.1:8005 0.0.0.0:* LISTEN 1617/java
tcp 0 0 0.0.0.0:8009 0.0.0.0:* LISTEN 1617/java
- 自定义jsp页面,并测试访问
[root@localhost bin]# mkdir -p /web/webapp/
[root@localhost bin]# vi /web/webapp/index.jsp
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<html>
<head>
<title>JSP TEST PAGE1 </title>
</head>
<body>
<% out.println("Welcome to test site;http://www.linux1.com");%>
</body>
</html>
[root@localhost bin]# vi /usr/local/tomcat/conf/server.xml
148 <Host name="localhost" appBase="webapps"
149 unpackWARs="true" autoDeploy="true">
150 <Context docBase="/web/webapp" path="" reloadable="false"></Context>
注解:
unpackWARs="true" ##设置自动识别war包
autoDeploy="true" ##开启自动部署
Context docBase="/web/webapp" ##设置项目存放位置
path="" ## tomcat把web应用程序映射为root URI路径reloadable="true" ## tomcat服务器在运行状态下会监视在WEB-INF/classes和WEB-INF/lib目录下class文件的改动,如果监测到代码中有class文件被更新的,服务器会自动重新加载Web应用,但是开启会加重服务器负荷,建议设置为false选项为关闭,有可能会出现内存溢出,tomcat服务不正常等异常,建议还是false掉,更新完代码脚本重启tomcat才是王道。;
[root@localhost bin]# /usr/local/tomcat/bin/shutdown.sh
[root@localhost bin]# /usr/local/tomcat/bin/startup.sh
Nginx优化
-
隐藏版本号
- 方式一
在配置文件修改 [root@localhost ~]# vi /data/nginx/conf/nginx.conf ##在http{}内添加即可 server_tokens off;- 方式二
修改源码包 [root@localhost ~]# vi /data/nginx-1.22.0/src/core/nginx.h #解压完修改 #define NGINX_VERSION "6.6.6" -
网页缓存
[root@localhost ~]# vi /data/nginx/conf/nginx.conf
location ~ \.(gif|jpg|jpeg|png|bmp|ico)$ {
expires 1d;
}
location ~ .*\.(js|css)$ {
expires 1h;
}
#配置禁用缓存:
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|js|css)$ {
add_header Cache-Control no-store;
}-
连接超时
- 作用:在企业中为了避免同一个用户长时间占用连接,造成服务器资源浪费,设置相应的连接超时参数,实现控制连接访问时间。
- 配置项
keepalived_timeout 设置连接保持超时时间,一般可只设置该参数,默认为 65 秒,可根据网站的情况设置,或者关闭,可在 http 段、 server 段、或者 location 段设置。 client_header_timeout 指定等待客户端发送请求头的超时时间。 client_body_timeout 设置请求体读取超时时间。 注意: 若出现超时,会返回 408 报错 -
网页传输压缩
- 作用:将服务端传输的网页文件压缩传输,使其更加快速、减少带宽的占用;
[root@localhost ~]# vi /data/nginx/conf/nginx.conf gzip on; ##开启 gzip 压缩输出 gzip_min_length 1k; ##用于设置允许压缩的页面最小字节数 gzip_buffers 4 16k; ##表示申请4 个单位为 16k 的内存作为压缩结果流缓存,默认值是申请与原始数据大小相同的内存空间来储存 gzip 压缩结果 gzip_http_version 1.1; # #设置识别 http 协议版本,默认是 1.1 gzip_comp_level 2; ##gzip 压缩比, 1-9 等级 gzip_types text/plain text/javascript application/x-javascript text/css text/xml application/xml application/xml+rss image/jpeg; ##压缩类型,是就对哪些网页文档启用压缩功能 -
访问控制
- 作用:限制访问网站资源
- 配置项
auth_basic "Nginx Status"; 认证提示文字 auth_basic_user_file /data/nginx/conf/user.conf; 认证用户文件,可以使用apache提供的htpasswd命令来生成文件 allow 192.168.100.101; 允许客户端ip地址 deny 192.168.100.0/24; 拒绝的网段例如
[root@localhost ~]# yum -y install httpd-tools [root@localhost ~]# htpasswd -c /data/nginx/conf/user.conf zs [root@localhost ~]# cat /data/nginx/conf/user.conf zs:VJVdQdVHEIvZo [root@localhost ~]# vi /data/nginx/conf/nginx.conf location /status { stub_status on; access_log off; auth_basic "Nginx Status"; auth_basic_user_file /usr/local/nginx/conf/user.conf; allow 192.168.100.101; deny 192.168.100.0/24; } -
定义错误页面
- 作用:根据客户端的访问网站的返回状态码,为其制定到特定的错误页面
- 配置
[root@localhost ~]# vi /data/nginx/conf/nginx.conf error_page 403 404 /404.html; location = /404.html { root html; } [root@localhost ~]# echo "deny" >>/usr/local/nginx/html/404.html -
自动索引
- 作用:将网站转化为ftp的站点,作为共享文件的工具
[root@localhost ~]# mkdir -p /data/nginx/html/download/test/ [root@localhost ~]# touch /data/nginx/html/download/test/{1..10}.txt [root@localhost ~]# vi /data/nginx/conf/nginx.conf location /download { autoindex on; } -
目录别名
- 作用:将域名后缀的路径设置一个别名,通过多种方式访问
- 配置
[root@localhost ~]# vi /data/nginx/conf/nginx.conf location /dw { alias /data/nginx/html/haha/; } [root@localhost ~]# mkdir /data/nginx/html/haha [root@localhost ~]# echo "haha" >/data/nginx/html/haha/index.html -
日志分割
-
脚本方式
- 剪切日志后,使用kill -USR1发送信号重新生成日志文件,同时还不影响网站请求处理进程。
- 错误时通过echo和tee -a命令将错误显示的同时写入到日志文件/var/log/messages。
[root@localhost ~]# vi /root/cut_nginx_log.sh #!/bin/bash datetime=$(date -d "-1 day" "+%Y%m%d") log_path="/data/nginx/logs" pid_path="/data/nginx/logs/nginx.pid" mkdir -p $log_path/backup if [ -f $pid_path ] then mv $log_path/access.log $log_path/backup/access.log-$datetime kill -USR1 $(cat $pid_path) find $log_path/backup -mtime +30 | xargs rm -f else echo "Error,Nginx is not working!" >> /var/log/messages fi :wq [root@localhost ~]# chmod +x /root/cut_nginx_log.sh [root@localhost ~]# echo "0 0 * * * /root/cut_nginx_log.sh" >>/var/spool/cron/root -
-
防盗链
-
防盗链就是防止别人盗用服务器中的图片、文件、视频等相关资源。防盗链:是通过location + rewrite实现的;
-
应用举例
location ~* \.(wma|wmv|asf|mp3|mmf|zip|rar|jpg|gif|png|swf|flv)$ { valid_referers none blocked *.linux.cn linux.cn; ##所有信任访问路径 if ($invalid_referer) { rewrite ^/ http://www.linux.cn/error.jpg; } 第一行: wma|wmv|asf|mp3|mmf|zip|rar|jpg|gif|png|swf|flv 表示对这些后缀的文件进行防盗链。 第二行:valid_referers表示被允许的信任URL,none表示浏览器中 referer(Referer 是 header 的一部分,当浏览器向 web 服务器发送请求的时候,一般会带上 Referer,告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理) 为空的情况,就直接在浏览器访问图片,blocked referer 不为空的情况,但是值被代理或防火墙删除了,这些值不以http://或 https://开头,*.linux是匹配URL的域名。 第三行:if{ }判断如果是来自于invalid_referer(不被允许的URL)链接,即不是来自第二行指定的URL,就强制跳转到错误页面,当然直接返回 404(return 404)也是可以的,也可以是图片。 注意:防盗链测试时,不要和expires配置一起使用。 -
-
rewrite地址url重写
- 作用:将客户端所访问的url进行重定向
- 语法
rewrite regex http://www.baidu.com/ 参数;
- 常用参数

-
虚拟主机
- 不同IP,不同域名,相同端口
server { listen 192.168.100.101:80; server_name www.linux1.cn; charset utf-8; access_log logs/linux1.access.log main; location / { root /var/www/linux1/; index index.html index.php; } } server { listen 192.168.100.102:80; server_name www.linux2.cn; charset utf-8; access_log logs/linux2.access.log main; location / { root /var/www/linux2/; index index.html index.php; } }- 相同IP,不同域名,相同端口
server { listen 192.168.100.101:80; server_name www.linux1.cn; charset utf-8; access_log logs/linux1.access.log main; location / { root /var/www/linux1/; index index.html index.php; } } server { listen 192.168.100.101:80; server_name www.linux2.cn; charset utf-8; access_log logs/linux2.access.log main; location / { root /var/www/linux2/; index index.html index.php; } }- 相同IP,不同端口,相同域名
server { listen 192.168.100.101:80; server_name www.linux1.cn; charset utf-8; access_log logs/linux1.access.log main; location / { root /var/www/linux1/; index index.html index.php; } } server { listen 192.168.100.101:81; server_name www.linux1.cn; charset utf-8; access_log logs/linux1.access.log main; location / { root /var/www/linux2/; index index.html index.php; } }


函数
函数:组织好的、可以重复利用的、用户实现单一或者关联功能的代码段,函数能够提高应用的模块性和代码的重复利用率。
函数的定义规则
函数代码块以def关键词开头,后接函数标识符名称和圆括号()
任何传入参数和自变量必须放在圆括号中间
函数的第一行语句可以选择性的使用文档字符串----用于存放函数说明
函数内容以冒号起始,并且缩进
定义函数
语法:
def 函数名([参数列表]): #参数列表可选项函数体
例如:
def PName(): #使用def定义一个函数PName()
print('hello world')
PName() #调用函数调用函数
python内置了很多函数,内置函数可以直接调用,调用一个函数需要知道函数的名称和函数的参数。
语法:
函数名([参数列表])
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋值给一个变量,相当于给这个函数起了一个别名。
例如:
student = [1,2,3,4,5]
a = len #变量a指向len函数
num = a(student) #可以通过a调用len函数
print('student列表元素的个数为:',num)
结果为:
student列表元素的个数为: 5
注意:
1.遇到行数定义时,不会去执行内部代码,只有遇到函数调用时,才会去执行函数体内部代码
2.执行完内部代码后,又回到调用函数的地方,继续向下执行
3.如果没有调用函数的话,函数体内部代码是不会执行的函数的参数
位置参数:调用函数时根据函数定义的参数位置来传递参数
例如:定义一个参数,函数有3个参数name,age,gender
def UserInfo(name,age,denger):
print(f'你的名字为:{name},年龄为:{age},性别为:{denger}')
UserInfo('张三',18,'男') #需要放实参,个数和位置需要和形参一一对应,否则报错
结果为:
你的名字为:张三,年龄为:18,性别为:男关键字参数:函数调用时通过"键" = "值"形式加以指定,可以让函数更加清晰、容易使用。
例如:
def getInfo(name,address):
print('大家好我叫%s,我来自%s'%(name,address))
getInfo(name='张三',address='西藏') #给实参加上关键字,关键字对应形参
结果为:
大家好我叫张三,我来自西藏参数的默认值:在声明函数的时候给形参先赋值,携带默认值形参放在最右边
例如一:
def getInfo(name,address = '西藏')
print('大家好我叫%s,我来自%s'%(name,address))
getInfo('张三') #有默认值的形参,可以不用传递
结果为:
大家好我叫张三,我来自西藏
例如二:
def getInfo(name,address = '西藏')
print('大家好我叫%s,我来自%s'%(name,address))
getInfo('张三','新疆') #传递参数,会覆盖原来的默认值
结果为:
大家好我叫张三,我来自新疆不定长参数:也叫可变参数,用于不确定会传递多少参数的时候使用;
*args是接收所有未命名的参数(关键字),返回的结果是元组类型;
**kwargs是接收所有命名的实参(关键字),返回的结果是字典类型
例如:
def getInfo(name,address,*args,**kwargs):
print('大家好我叫%s,我来自%s'%(name,address))
print(args) #返回是元组类型
print(kwargs) #返回是字典类型
getInfo('张三','新疆','a','b','c',age = 18)
结果为:
大家好我叫张三,我来自新疆
('a','b','c')
{'age',18}可变对象与不可变对象(传递的时候)
不可变类型:如整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在fun(a)内部修改a的值,只是修改另一个赋值的对象,不会影响a本身。
例如:
def sign(): #自定义函数
print('_'*30)
#值传递 不可变对象传递
def fun(args)
args = 'hello' #重新赋值
print(args) #输出hello
str = 'baby' #声明一个字符串变量,不可变数据类型
fun(str1) #将该字符串传递到函数中
sign()
print(str1) #还是baby,并没有被改变
结果为:
hello
------------------------------
baby可变类型:如列表、字典。如fun(la),则是将la真正的传递过去,修改后fun外部的la也会受到影响
例如:
def sign(): #自定义函数
print('_'*30)
#引用传递 可变对象传递
def fun(args):
args[0] = 'hello' #重新赋值
print(args) #输出hello
list1 = ['baby','come on'] #声明一个字符变量,可变数据类型
fun(list1) #将该字符传递到函数中
sign()
print(list1) #传递的对象本身,函数里面被修改了值,源对象也会修改
结果为:
['hello', 'come on']
------------------------------
['hello', 'come on']
函数的返回值
函数并非总是将结果直接输出,相反,函数的调用者需要函数提供一些通过函数处理过后的一个或者一组数据,只有调用者拥有了这个数据,才能够做一些其他的操作。那么这个时候,就需要函数返回给调用者数据,这个就被成为返回值,想要在函数中把结果返回给调用者,需要在函数中使用return。
return语句:用于退出函数,选择性的向调用者返回一个表达式。直接return的语句返回None。
def max(x,y):
if x > y:
return x #结束函数的运行,并且将结果返回给调用的地方
else:
return y
# print(y) #没有执行代码
#return后的代码不会执行
#调用函数 接收返回值
num = max(3,2) #声明一个变量num接收调用的函数后的返回值
print(num) #观察接收的返回值
结果为:
3return返回多个值
def sum(x,y):
return x,y
num = sum(1,2) #用一个变量接收多个返回值时,会保存在一个元组中
print(num)
num1,num2 = sum(1,2)
print(num1)
print(num2)
结果为:
(1, 2)
1
2yield 生成器:把一个函数变成一个generator,使用生成器可以达到延迟操作的效果,所谓延迟操作就是指在需要的时候产生结果,而不是立即产生结果,节省资源消耗和声明一个序列不同的生成器,在不使用的时候几乎是不占内存。
例如:
def getNum(n):
i = 0
while i <= n:
yield i #将函数变成一个generator生成器对象
i += 1
# 调用函数
getNum(5)
a = getNum(5) #把生成器赋值给一个变量a
# 使用生成器,通过next()方法
print(next(a)) #输出yield返回的值,输出一次返回一个值
print(next(a))
结果为:
0
1例如:
#for循环遍历一个生成器
a = (x for x in range(10000000)) #是一个生成器,不是元组推导式
print(a)
for i in a:
print(next(a))send():把值传进当前的yield
例如:
def gen():
i = 0
while i <=5:
temp = yield i #不是一个赋值
#使用yield是一个生成器
print(temp) #因为yield之后返回结果到调用者的地方,暂停运行
i += 1
a = gen()
next(a)
print(a.send('我是a')) #可以将值发送到上一次yield的地方
结果为:
我是a
1迭代器
迭代对象:
可以用for i in 遍历的对象可以叫做迭代对象:Iterable
如可迭代对象:list string dict
可以被next()函数调用的并不断返回下一个值的对象叫做迭代器:iterator
凡是可以用作与next()函数的对象都是iterator迭代器例如:
list01 = [1,2,3,4,5] #是一个可迭代对象
#通过iter()将可迭代对象变成迭代器
a = iter(list01)
print(next(a))
print(next(a))
结果为:
1
2变量的作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
局部变量:声明在函数内部的变量,局部变量的作用域只在于函数中,外部无法使用
例如:
def test01():
a = 10
print('-----修改前的a:%d'%(a))
print(id(a))
a = 20
print('-----修改后的a:%d'%(a))
print(id(a))
def test02():
a = 40
print('-----我是test02的a:%d'%(a))
print(id(a))
test01()
test02()
结果为:
-----修改前的a:10
140722366292672
-----修改后的a:20
140722366292992
-----我是test02的a:40
140722366293632全局变量:声明在函数外部的变量,大家共同使用;
a = 100
print('打印全局变量a:%d'%(a))
print(id(a))
def test1():
print('在test1函数内部使用全局变量a:%d'%(a))
print(id(a))
def test2():
print('在test2函数内部使用全局变量a:%d'%(a))
print(id(a))
#调用函数
test1()
test2()
结果为:
打印全局变量a:100
140722366295552
在test1函数内部使用全局变量a:100
140722366295552
在test2函数内部使用全局变量a:100
140722366295552修改全局变量:global关键字
a = 100
print('打印全局变量a:%d'%(a))
print(id(a))
def test1():
global a
a = 200
print('在test1函数内部使用修改全局变量a:%d'%(a))
print(id(a))
def test2():
print('在test2函数内部使用全局变量a:%d'%(a))
print(id(a))
#调用函数
test1()
test2()
print('打印全局变量a:%d'%(a))
print(id(a))
结果为:
打印全局变量a:100
140722366295552
在test1函数内部使用修改全局变量a:200
140722366298752
在test2函数内部使用全局变量a:200
140722366298752
打印全局变量a:200
140722366298752匿名函数:定义函数的过程中,没有给定名称的函数,python中使用lambda表达式来创建匿名函数
lambda创建匿名函数规则
lambda 参数列表:表达式
lambda只是一个表达式,函数体比def简单很多
lambda的主体是一个表达式,而不是一个代码块,所以不能写太多的逻辑进去
lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间的参数
lambda定义的函数的返回值就是表达式的返回值,不需要return语句块
lambda表达式的主要应用场景就是复制给变量、作为参数传入其他函数例如:
1.没有参数的匿名函数
s = lambda : '哈哈哈'
print(s())
结果为:
哈哈哈
2.有参数的匿名函数
s = lambda x,y : x + y
print(s(3,3))
结果为:
6
3.矢量化的三元运算符
s = lambda x,y : x if x > 2 else y
print(s(3,5))
结果为:
3需求:字典排序
dic = {'a':1,'c':2,'b':3}
dic = sorted(dic.items(),key=lambda x:x[1],reverse= True)
print({k:v for k,v in dic})
结果为:
{'b': 3, 'c': 2, 'a': 1}
需求:列表排序
list01 = [
{'name':'joe','age':18},
{'name':'susan','age':19},
{'name':'tom','age':17}
]
dic = sorted(list01,key = lambda x:x['age'],reverse= True) #reverse=True 是倒序,由大到小,reverse=False或者不填是正序,有小到大
print(dic)
结果为:
[{'name': 'susan', 'age': 19}, {'name': 'joe', 'age': 18}, {'name': 'tom', 'age': 17}]递归函数:递归就是子程序(或函数)直接调用自己或通过一系列调用语句简介调用自己,是一种描述问题和解决问题的基本方法。
例如:
def main(n):
print('进入第%d层梦境'%n)
if n == 3:
print('到达潜意识区,开始醒来')
else:
main(n+1)
print('从第%d层梦境醒来'%n)
main(1)
结果为:
进入第1层梦境
进入第2层梦境
进入第3层梦境
到达潜意识区,开始醒来
从第3层梦境醒来
从第2层梦境醒来
从第1层梦境醒来计算阶乘
def jiecheng(n):
if n == 1:
return 1
else:
return n * jiecheng(n-1)
print(jiecheng(10))
结果为:
3628800高阶函数:将一个函数做为参数传递到另一个函数A中,那个这个函数A就是高阶函数
map接收一个函数及多个集合序列,会根据提供的函数对指定序列做映射,然后返回一个新的map
例如:
list01 = [1,3,5,7,9]
list02 = [2,4,6,8,10]
new_list = map(lambda x,y:x * y,list01,list02)
print(list(new_list)) #将map对象转换为list
结果为:
[2, 12, 30, 56, 90]filter用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的filter对象
list02 = [2,4,6,8,10]
new_list = filter(lambda x:x > 4,list02)
print(list(new_list))
结果为:
[6, 8, 10]reduce对于序列中的所有元素用func进行数据合并操作,可以给定一个初始值
from functools import reduce
list02 = [2,4,6,8,10]
new_list = reduce(lambda x,y:x+y,list02)
print(new_list)
结果为:
30将rpm包制作成本地yum安装方式进行依赖安装
日常系统安装rpm,在没有网络且本地镜像没有包的情况下安装是很头疼的一件事,有得rpm包不仅是自身那一个包,他还要依赖于很多其他的包,因此安装就是很费劲很麻烦的事情,这样我们可以在自己本地现下载,然后将所用的包括需要使用的rpm,与其他依赖一起进行安装。
1.下载所需要的包
将rpm下载至本地格式为:
yum install --downloadonly --downloaddir=下载的目录名 rpm包名
其中--downloadonly:仅下载的意思
例:
[root@localhost ~]# yum install --downloadonly --downloaddir=/root/yum/Packages gcc make binutils gcc-c++ compat-libstdc++-33 elfutils-libelf-devel elfutils-libelf-devel-static ksh libaio libaio-devel numactl-devel sysstat unixODBC unixODBC-devel pcre-develcd2.创建自己的yum
安装createrepo制作本地yum的工具
[root@localhost ~]# yum -y install createrepo
[root@localhost yum]# ls
Packages
[root@localhost yum]# createrepo ./ 创建本地的yum
Spawning worker 0 with 30 pkgs
Workers Finished
Saving Primary metadata
Saving file lists metadata
Saving other metadata
Generating sqlite DBs
Sqlite DBs complete
#执行完成后发现有生成repodata目录
[root@localhost yum]# ll
总用量 8
drwxr-xr-x 2 root root 4096 4月 2 21:40 Packages
drwxr-xr-x 2 root root 4096 4月 2 21:42 repodata
[root@localhost yum]# cd repodata/
[root@localhost repodata]# ls
2e776079c9688b5b25ce39976392c1f522e4eb0a135d9d759ff4975583302402-other.xml.gz
48103ebfa5b33d8f4d35b78242cebbbc53cc5a7c63e61e2cadc8391b6c08c846-primary.sqlite.bz2
8f27acc719e269ef8f8fba05e6b8124438e06730af66e1043b39aef6c07fa624-filelists.xml.gz
96f7c794f560975631925daf05e1a1f09a90d65f8902a01080655972ee0733f6-filelists.sqlite.bz2
beaeddc565a92cdf1948a9fabbf884bfbe8dcc4f010907712043454a552f4e26-other.sqlite.bz2
de97a7aab0273d45e9fe6e20d08d5afeda1880c556be3768e5430dbe58158931-primary.xml.gz
repomd.xml3.配置本地yum仓库
其中以repo后缀的名称随意命名
[root@localhost ~]# vi /etc/yum.repos.d/centos.repo
[local] #仓库的名字,随意创建
name=local #仓库名字的解释说明
baseurl=file:///root/yum #仓库的路径
enable=1 #启用此yum仓库
gpgcheck=0 #是否开启公钥校验4.清空yum源、更新yum源、查看已加载新yum源
[root@localhost ~]# yum clean all
已加载插件:fastestmirror
正在清理软件源: local
Cleaning up everything
Maybe you want: rm -rf /var/cache/yum, to also free up space taken by orphaned data from disabled or removed repos
Cleaning up list of fastest mirrors
[root@localhost ~]# yum makecache
已加载插件:fastestmirror
local | 2.9 kB 00:00:00
(1/3): local/filelists_db | 18 kB 00:00:00
(2/3): local/other_db | 15 kB 00:00:00
(3/3): local/primary_db | 22 kB 00:00:00
Determining fastest mirrors
元数据缓存已建立
[root@localhost ~]# yum repolist all
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
源标识 源名称 状态
local local 启用: 30
repolist: 305.安装验证
[root@localhost ~]# yum -y install gcc make binutils gcc-c++ compat-libstdc++-33 elfutils-libelf-devel elfutils-libelf-devel-static ksh libaio libaio-devel numactl-devel sysstat unixODBC unixODBC-devel pcre-devel
已加载插件:fastestmirror
local | 2.9 kB 00:00:00
local/primary_db | 22 kB 00:00:00
Loading mirror speeds from cached hostfile
正在解决依赖关系
--> 正在检查事务
---> 软件包 binutils.x86_64.0.2.25.1-31.base.el7 将被 升级
---> 软件包 binutils.x86_64.0.2.27-44.base.el7_9.1 将被 更新
---> 软件包 compat-libstdc++-33.x86_64.0.3.2.3-72.el7 将被 安装
---> 软件包 elfutils-libelf-devel.x86_64.0.0.176-5.el7 将被 安装
--> 正在处理依赖关系 elfutils-libelf(x86-64) = 0.176-5.el7,它被软件包 elfutils-libelf-devel-0.176-5.el7.x86_64 需要
--> 正在处理依赖关系 pkgconfig(zlib),它被软件包 elfutils-libelf-devel-0.176-5.el7.x86_64 需要
...
作为依赖被升级:
cpp.x86_64 0:4.8.5-44.el7 elfutils.x86_64 0:0.176-5.el7 elfutils-libelf.x86_64 0:0.176-5.el7 elfutils-libs.x86_64 0:0.176-5.el7
gcc-gfortran.x86_64 0:4.8.5-44.el7 libgcc.x86_64 0:4.8.5-44.el7 libgfortran.x86_64 0:4.8.5-44.el7 libgomp.x86_64 0:4.8.5-44.el7
libquadmath.x86_64 0:4.8.5-44.el7 libquadmath-devel.x86_64 0:4.8.5- 44.el7 libstdc++.x86_64 0:4.8.5-44.el7 libstdc++-devel.x86_64 0:4.8.5-44.el7
numactl-libs.x86_64 0:2.0.12-5.el7 zlib.x86_64 0:1.2.7-19.el7_9
完毕!至此本地yum就创建完成了,希望对你有帮助!
elasticsearch集群
elasticsearch集群安装
elasticsearch简介
elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。一、为什么要搭建集群?
(1)高可用性
Elasticsearch 作为一个搜索引擎,我们对它的基本要求就是存储海量数据并且可以在非常短的时间内查询到我们想要的信息。所以第一步我们需要保证的就是 Elasticsearch 的高可用性,什么是高可用性呢?它通常是指,通过设计减少系统不能提供服务的时间。假设系统一直能够提供服务,我们说系统的可用性是 100%。如果系统在某个时刻宕掉了,比如某个网站在某个时间挂掉了,那么就可以它临时是不可用的。所以,为了保证 Elasticsearch 的高可用性,我们就应该尽量减少 Elasticsearch 的不可用时间。
那么怎样提高 Elasticsearch 的高可用性呢?这时集群的作用就体现出来了。假如 Elasticsearch 只放在一台服务器上,即单机运行,假如这台主机突然断网了或者被攻击了,那么整个 Elasticsearch 的服务就不可用了。但如果改成 Elasticsearch 集群的话,有一台主机宕机了,还有其他的主机可以支撑,这样就仍然可以保证服务是可用的。
那可能有的小伙伴就会说了,那假如一台主机宕机了,那么不就无法访问这台主机的数据了吗?那假如我要访问的数据正好存在这台主机上,那不就获取不到了吗?难道其他的主机里面也存了一份一模一样的数据?那这岂不是很浪费吗?
为了解答这个问题,这里就引出了 Elasticsearch 的信息存储机制了。首先解答上面的问题,一台主机宕机了,这台主机里面存的数据依然是可以被访问到的,因为在其他的主机上也有备份,但备份的时候也不是整台主机备份,是分片备份的,那这里就又引出了一个概念——分片。分片,英文叫做 Shard,顾名思义,分片就是对数据切分成了多个部分。我们知道 Elasticsearch 中一个索引(Index)相当于是一个数据库,如存某网站的用户信息,我们就建一个名为 user 的索引。但索引存储的时候并不是整个存一起的,它是被分片存储的,Elasticsearch 默认会把一个索引分成五个分片,当然这个数字是可以自定义的。分片是数据的容器,数据保存在分片内,分片又被分配到集群内的各个节点里。当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里,所以相当于一份数据被分成了多份并保存在不同的主机上。
那这还是没解决问题啊,如果一台主机挂掉了,那么这个分片里面的数据不就无法访问了?别的主机都是存储的其他的分片。其实是可以访问的,因为其他主机存储了这个分片的备份,叫做副本,这里就引出了另外一个概念——副本。
副本,英文叫做 Replica,同样顾名思义,副本就是对原分片的复制,和原分片的内容是一样的,Elasticsearch 默认会生成一份副本,所以相当于是五个原分片和五个分片副本,相当于一份数据存了两份,并分了十个分片,当然副本的数量也是可以自定义的。这时我们只需要将某个分片的副本存在另外一台主机上,这样当某台主机宕机了,我们依然还可以从另外一台主机的副本中找到对应的数据。所以从外部来看,数据结果是没有任何区别的。
一般来说,Elasticsearch 会尽量把一个索引的不同分片存储在不同的主机上,分片的副本也尽可能存在不同的主机上,这样可以提高容错率,从而提高高可用性。
但这时假如你只有一台主机,那不就没办法了吗?分片和副本其实是没意义的,一台主机挂掉了,就全挂掉了。
(2)健康状态
针对一个索引,Elasticsearch 中其实有专门的衡量索引健康状况的标志,分为三个等级:
-
green ,绿色。这代表所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
-
yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果更多的分片消失,你就会丢数据了。所以可把 yellow 想象成一个需要及时调查的警告。
-
red,红色。至少一个主分片以及它的全部副本都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
如果你只有一台主机的话,其实索引的健康状况也是 yellow,因为一台主机,集群没有其他的主机可以防止副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的。
(3)存储空间
另外,既然是群集,那么存储空间肯定也是联合起来的,假如一台主机的存储空间是固定的,那么集群它相对于单个主机也有更多的存储空间,可存储的数据量也更大。所以综上所述,我们需要一个集群!
二、详细了解 Elasticsearch 集群
接下来我们再来了解下集群的结构是怎样的。
首先我们应该清楚多台主机构成了一个集群,每台主机称作一个节点(Node)。
如图就是一个三节点的集群:

在图中,每个 Node 都有三个分片,其中 P 开头的代表 Primary 分片,即主分片,R 开头的代表 Replica 分片,即副本分片。所以图中主分片 1、2,副本分片 0 储存在 1 号节点,副本分片 0、1、2 储存在 2 号节点,主分片 0 和副本分片 1、2 储存在 3 号节点,一共是 3 个主分片和 6 个副本分片。同时我们还注意到 1 号节点还有个 MASTER 的标识,这代表它是一个主节点,它相比其他的节点更加特殊,它有权限控制整个集群,比如资源的分配、节点的修改等等。
这里就引出了一个概念就是节点的类型,我们可以将节点分为这么四个类型:
主节点:即 Master 节点。主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。默认情况下任何一个集群中的节点都有可能被选为主节点。索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
数据节点:即 Data 节点。数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对 CPU、内存、IO 要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
负载均衡节点:也称作 Client 节点,也称作客户端节点。当一个节点既不配置为主节点,也不配置为数据节点时,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
预处理节:点也称作 Ingest 节点,在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。
以上就是节点几种类型,一个节点其实可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但如果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
三、搭建 Elasticsearch 集群
准备环境
| 系统环境 | 节点名称 | IP地址 | 安装包 |
|---|---|---|---|
| centos7.8 | es1 | 192.168.100.101 | elasticsearch-7.6.0-linux-x86_64.tar.gz |
| centos7.8 | es2 | 192.168.100.102 | elasticsearch-7.6.0-linux-x86_64.tar.gz |
| centos7.8 | es3 | 192.168.100.103 | elasticsearch-7.6.0-linux-x86_64.tar.gz |
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本。通过将一个单独的索引分为多个分片,我们可以处理不能在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。(1)安装JDK
Elasticsearch是基于Java开发是一个Java程序,运行在jvm中,所以第一步要安装JDK。
[root@es1 ~]#yum install -y java-1.8.0-openjdk-devel # 安装1.8或1.8以上版本(2)创建es用户,三台一样;
[root@es1 ~]#groupadd es
[root@es1 ~]#useradd es -g es
[root@es1 ~]#passwd es (密码123123)(3)创建安装目录,且修改响应参数
[root@es1 ~]#mkdir /data修改系统参数,因为文件描述符内核高效管理一被打开的文件所创建的索引,用于指向被打开的文件,所有执行I/O操作的系统调用都通过文件描述符太少,至少要【65535】个,所以修改;
[root@es1 ~]#vim /etc/security/limits.conf #追加
root soft nofile 65535
root hard nofile 65535
* soft nofile 65536
* hard nofile 65536
保存退出,重新连接验证;
[root@es1 ~]#ulimit -S -n #查看软件资源限制
[root@es1 ~]#ulimit -H -n #查看硬件资源限制修改max_map_count 文件,该文件包含限制一个进程可以拥有的VMA的数量。虚拟内存区域是一个连续的虚拟地址空间区域;
[root@es1 ~]#vim /etc/sysctl.conf #追加
vm.max_map_count=655360
[root@es1 ~]#sysctl -p #重新加载使生效(6)解压elasticsearch,且修改配置
[root@es1 ~]#tar xf elasticsearch-7.6.0-linux-x86_64.tar.gz -C /data
[root@es1 ~]#mv /data/elasticsearch-7.6.0/ /data/elasticsearch #改名称,方便好记;
[root@es1 ~]#chown -R es.es /data/elasticsearch/ #赋权限,最好用赋权用户启动;修改配置文件,修改如下内容
[root@es1 ~]# vi /data/elasticsearch/config/elasticsearch.yml
cluster.name: my-es
node.name: es1
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
network.host: 192.168.100.101
http.port: 9200
discovery.seed_hosts: ["192.168.100.101", "192.168.100.102", "192.168.100.103"] #可以用IP,可以用域名,需要在/etc/hosts文件中提前加好;
cluster.initial_master_nodes: ["192.168.100.101", "192.168.100.102", "192.168.100.103"] #可以用IP,可以用域名,需要在/etc/hosts文件中提前加好;
末尾追加
http.cors.enabled: true // 是否开启跨域访问,默认是false;
http.cors.allow-origin: "*" // 可以访问的域名,* 代表任意都可以访问;修改jvm.options,原因可能出现如下错误信息

[root@es1 ~]# vi /data/elasticsearch/config/jvm.options
-Xms1g 修改为 ===> -Xms2g
-Xmx1g 修改为 ===> -Xmx2g
设置为物理内存一半最佳,可根据服务器内存去选择调;创建数据存储目录
[root@es1 ~]#mkdir -p /data/elasticsearch/data
赋予权限
[root@es1 ~]#chown -R es.es /data/elasticsearch/data(7)切换es用户启动且验证
[root@es1 ~]#su - es
[root@es1 ~]#cd /data/elasticsearch/bin
[root@es1 ~]#./elasticsearch -d 后台运行查看单节点状态
[root@es1 ~]# curl http://192.168.100.101:9200
{
"name" : "es1",
"cluster_name" : "my-es",
"cluster_uuid" : "t5WZUYtnR-CPBhweUsAilg",
"version" : {
"number" : "7.6.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "7f634e9f44834fbc12724506cc1da681b0c3b1e3",
"build_date" : "2020-02-06T00:09:00.449973Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}查看集群状态
[root@es1 ~]# curl http://192.168.100.101:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.100.101 22 96 0 0.00 0.02 0.05 dilm * es1
192.168.100.103 26 96 0 0.00 0.01 0.05 dilm - es3
192.168.100.102 47 97 0 0.00 0.02 0.05 dilm - es2
[root@es1 ~]# curl http://192.168.100.101:9200/_cluster/health?pretty
{
"cluster_name" : "my-es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}以上简单的elasticsearch集群就搭建好了!
zookeeper+mq集群
zookeeper集群+activemq集群搭建
一、zookeeper介绍
ZooKeeper:它是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等!
二、zookeeper集群搭建
1.基础环境
| IP/名称 | 操作系统 | 服务端口 | 集群通信端口 | 节点目录 | 应用版本 |
|---|---|---|---|---|---|
| 192.168.100.106/zk1 | centos7.8 | 2181 | 2881:3881 | /usr/local/zookeeper | zookeeper-3.4.5.tar.gz |
| 192.168.100.107zk2 | centos7.8 | 2181 | 2881:3881 | /usr/local/zookeeper | zookeeper-3.4.5.tar.gz |
| 192.168.100.108/zk3 | centos7.8 | 2181 | 2881:3881 | /usr/local/zookeeper | zookeeper-3.4.5.tar.gz |
2.安装jdk
本次演示jdk安装为方便,用yum安装,三个节点一样
[root@zk1 ~]# yum install -y java-1.8.0-openjdk-devel3.解压安装
[root@zk1 ~]# tar xf zookeeper-3.4.5.tar.gz -C /usr/local/
[root@zk1 ~]# mv /usr/local/zookeeper-3.4.5 /usr/local/zookeeper
[root@zk1 ~]# cd /usr/local/zookeeper/conf/
[root@zk1 ~]# mv zoo_sample.cfg zoo.cfg4.修改配置
[root@zk1 ~]# vi zoo.cfg
#修改数据存储目录与添加日志存储目录,添加完成后创建该目录
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
#服务端口,根据实际情况修改
clientPort=2181
#末尾添加zk集群之间通讯端口
server.1=192.168.100.106:2881:3881
server.2=192.168.100.107:2881:3881
server.3=192.168.100.108:2881:38815.创建zk1 myid文件
#进入zookeeper目录中
[root@zk1 ~]# cd /usr/local/zookeeper/
[root@zk1 zookeeper]# mkdir data #创建数据存储目录
[root@zk1 zookeeper]# mkdir log #创建日志存储目录
[root@zk1 zookeeper]# cd data #进入数据存储目录
[root@zk1 data]# vi myid #添加server id
#演示为192.168.100.106,为zk1所以添加1,以此类推zk2为2,zk3为3
16.启动并查看
[root@zk1 data]# /usr/local/zookeeper/bin/zkServer.sh start
[root@zk1 data]# /usr/local/zookeeper/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader #集群启动成功后有一个为master节点
[root@zk2 ~]# /usr/local/zookeeper/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower #集群启动成功后为slave节点
[root@zk3 ~]# /usr/local/zookeeper/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower #集群启动成功后为slave节点三、activemq介绍
MQ是消息中间件,是一种在分布式系统中应用程序借以传递消息的媒介,常用的有ActiveMQ,RabbitMQ,kafka。ActiveMQ是Apache下的开源项目,完全支持JMS1.1和J2EE1.4规范的JMS Provider实现。 特点:
1、支持多种语言编写客户端
2、对spring的支持,很容易和spring整合
3、支持多种传输协议:TCP,SSL,NIO,UDP等
4、支持AJAX
优点:提高数据的安全性,提高资源的使用率
四、activemq搭建
1.基础环境
| IP/名称 | 操作系统 | 服务端口 | jetty控制台端口 | 节点目录 | 应用版本 |
|---|---|---|---|---|---|
| 192.168.100.106/zk1 | centos7.8 | 61616 | 8161 | /usr/local/activemq | apache-activemq-5.11.1-bin.tar.gz |
| 192.168.100.107zk2 | centos7.8 | 61616 | 8161 | /usr/local/activemq | apache-activemq-5.11.1-bin.tar.gz |
| 192.168.100.108/zk3 | centos7.8 | 61616 | 8161 | /usr/local/activemq | apache-activemq-5.11.1-bin.tar.gz |
2.创建安装目录,解压并安装,3个节点一致
[root@zk1 ~]# tar xf apache-activemq-5.11.1-bin.tar.gz -C /usr/local/
[root@zk1 ~]# mv /usr/local/apache-activemq-5.11.1 /usr/local/activemq
3.修改服务端口(activemq.xml)
[root@zk1 ~]# cd /usr/local/activemq/conf/
[root@zk1 conf]# vi activemq.xml
#根据实际情况修改默认端口
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
#修改持久化策略
<persistenceAdapter>
<replicatedLevelDB
directory="${activemq.data}/levelDB"
replicas="3" #当前主从模型中的节点数,根据实际配置
bind="tcp://192.168.100.106:62626" #主从实例间的通讯端口。
#这里要与zookeeeper的通信地址相对应
zkAddress="192.168.100.106:2181,192.168.100.107:2181,192.168.100.108:2181"
zkPath="/activemq/leveldb-stores" hostname="192.168.100.106" /> #ActiveMQ实例安装的实际linux主机名,可以在/etc/hosts配置文件中设置
</persistenceAdapter>4.修改控制台端口jetty.xml
[root@zk1 conf]# vi jetty.xml
<bean id="jettyPort" class="org.apache.activemq.web.WebConsolePort" init-method="start">
<!-- the default port number for the web console -->
<property name="host" value="0.0.0.0"/>
<property name="port" value="8161"/>
</bean>5.启动并验证
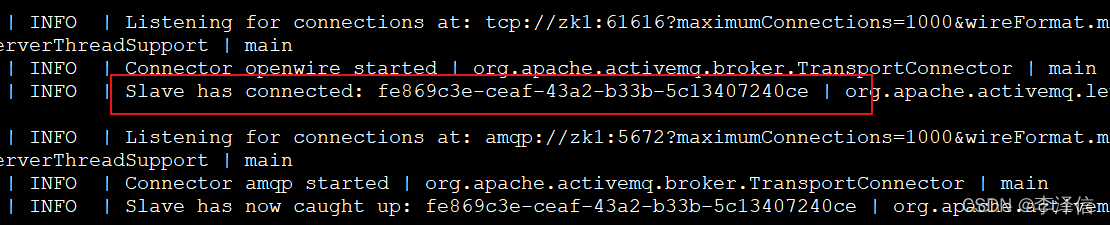
ActiveMQ的主从模型,是一种高可用的解决方案,在zookeeper中注册若干的ActiveMQ Broker,其中只有一台作为主机master对外提供服务,其他作为备份slave保持待机。当master出现问题导致宕机不能正常提供服务的时候,zookeeper通过内部选举,在众多slave中推举出一台作为master继续对外提供服务。
activemq集群最多支持损坏一个节点,若损坏2台,集群所有节点将停止运行。
集群中只有master对外提供服务,其他两个slave不对外提供服务,当访问activemq管理后台时,可以用netstat -uanpt|grep 端口,查看哪个节点端口运行,就可以使用哪个节点。
[root@zk1 conf]# /usr/local/activemq/bin/activemq start
[root@zk1 conf]# netstat -antup | grep 8161
tcp 0 0 0.0.0.0:8161 0.0.0.0:* LISTEN 15629/java6.查看data下日志状态
[root@zk1 data]# tail -100f activemq.logmaster启动

slave启动
网页验证IP+master端口